Le 18 mars 2018, un véhicule autonome de l’entreprise Uber percute un piéton dans l’Arizona. C’est le premier accident mortel lié au véhicule autonome. Ce triste constat, repris par la presse et par les entreprises qui développent ces modèles de voitures, est analysé par Boris Beaude, professeur en cultures, sociétés et humanités numériques à Université de Lausanne. Il annonce de facto « on appelle cela intelligence car il y a un processus cognitif de traitement mais cela n’a pas beaucoup de rapport avec notre façon de raisonner1 ». En effet, on peut trouver un bon nombre de spéculations sur le terme d’intelligence artificielle mais celle-ci reste cantonnée à des environnements de calculs très spécifiques. L’intelligence artificielle utilise un algorithme d’apprentissage automatique, appelée aussi Machine Learning. C’est un apprentissage qui utilise des données brutes, jusqu’à produire un modèle. Puis le modèle peut être utilisé pour faire des prédictions. Par l’apprentissage, l’algorithme élabore des catégories qui relèvent du signe. En effet, la machine développe un système spécifique par rapport aux données qu’il analyse. L’algorithme suit les motifs récurrents qu’il a aperçu lors de son apprentissage. Cependant sa réflexion suit un modèle « boîte noire », c’est-à-dire que personne ne sait comment l’algorithme arrive à son résultat computationnel. L’étude des systèmes de signes formalisés par la machine permet ainsi de mieux comprendre son fonctionnement et sa propre compréhension des données. Notre langage formalise notre façon d’appréhender le monde, qu’en est-il de la machine ? Dans le cas des véhicules autonomes, plusieurs algorithmes fonctionnent simultanément : celui qui nous intéresse pour comprendre le dramatique accident est celui de reconnaissance d’images. Comment la machine élabore-elle un concept ? Comment la machine peut comprendre un signe, alors qu’elle n’a à priori aucune connaissance du concept. C’est ce que l’on peut penser après l’accident. Évidemment, le système embarqué a connaissance du concept de « piéton ». Boris Beaude dans son exposé montre des exemples de vidéos de dashcams (caméras embarquées à l’avant d’une voiture retranscrivant la vue du pilote), issus de modèle de voiture Tesla. Les vidéos montrent des exemples de machine vision où les véhicules s'arrêtent aux passages des piétons. D’où vient l’accident ? Défauts dans les capteurs2 ou défauts dans l’algorithme utilisé, c’est à dire dans le système de signes produit par l’IA ? L’algorithme prend en entrée les différentes images des capteurs : chaque pixel est analysé mais aucun ne fournissent dans l’absolu de données tangibles. Indépendamment, les pixels n’ont aucune valeur. Est-ce que la silhouette n’a pas été perçue par l’algorithme d’Uber à cause du fait que l’individu traversait avec un vélo ? La police américaine mène l’enquête : elle dispose en tout cas d’une multitude de preuves avec l’enregistrement automatique de toutes les données par ces systèmes. Dans ce contexte du développement de la voiture autonome le Massachusetts Institute of Technology (M.I.T) propose le projet Moral Machine. Sur ledit site les utilisateurs peuvent choisir ce qu’une machine autonome devrait faire, dans le cas où le système de frein de la voiture est défaillant et qu’elle est obligée de renverser des personnes. L’utilisateur a un dilemme moral : renverser des personnes âgées sur un passage piéton ou des enfants. Ou encore des cadres et médecins face à des personnes sans domiciles fixes. Les choix des utilisateurs sont enregistrés dans le cadre d’une étude. La plateforme a pour objectif de produire un débat au sein de la société sur les éventuels scénarios et de leur conséquence morale ainsi que d’élaborer une opinion sur la façon dont les machines doivent prendre des décisions. Pour Boris Beaude, cette analyse ne correspond pas à la réalité : la machine est capable de distinguer un individu mais elle n’est pas assez pointue pour extraire toutes ces caractéristiques depuis un capteur, encore plus improbable qu’elle y arrive en un instant. Contrairement à ce qu’indique le MIT les systèmes de signes restent donc restreints. Les systèmes autonomes restent limités dans leur appréhension du monde et dans leur faculté à produire un comportement moral. D’après Boris Beaude, le tragique accident ayant eu lieu en Arizona ne fait que ralentir le temps d’adoption de cette technologie qui s’avère provoquer moins d’accident que la conduite traditionnelle. Le domaine du Machine Learning s’est démocratisé dans l’univers des sciences informatiques. Il s’applique à tous domaines pour la reconnaissance d’images en passant par la classification de documents numériques, de compréhension de textes, production d’images. L’intelligence artificielle pose un bon nombre de questionnement quant à sa capacité d’apprentissage et sur ces nouvelles méthodologies à base d’exemples. La notion même d’intelligence est complexe et elle a provoqué de vifs débats entre les psychologues et les philosophes au courant du XXe siècle, comme l’indique Catherine Malabou : Si les psychologues affirment que la notions d’intelligence recouvre une série de données empiriques, ils échouent cependant, selon les philosophes, à dire ce qu’elle est, à expliquer ce que signifie “être intelligent”. Tout se passe comme si l'intelligence existait sans avoir d’être3 Ainsi l’intelligence reste pour les psychologues qu’une forme d’axiomes indémontrables depuis lesquelles peut découler une réflexion. D’un point de vue étymologique Catherine Malabou écrit : « intelligentia » désigne la « faculté de comprendre », que le préfixe « inter » et le radical « legere » (« choisir », « cueillir ») ou ligare (« relier ») permettent d’interpréter comme capacité d’établir des rapports entre les choses, ils emploient plus volontiers le terme d’ « intellect4 » La notion s’articule étymologiquement donc entre notre capacité de choisir – trier, des informations et de les relier — de les interpréter. La réflexion se produit dans notre faculté à relier des choses. Yann Lecun, chercheur en intelligence artificielle et initiateur de la méthode du Deep Learning s’inspire grandement des neurosciences pour établir ses modèles algorithmiques. Comment s’articule les méthodes d’apprentissages de ces nouveaux algorithmes ? Pour classer des données, ces algorithmes doivent élaborer une méthodologie pour trier, ordonner et ranger chaque item — ils doivent élaborer des systèmes de signes. Comment s’organise ces systèmes ? Le terme signe vient du latin signum, marque, signe, empreinte, sceau ou cachet. Il est un indice, la marque d’une chose, il sert à représenter quelque chose. Ce terme à une signification plus particulière dans le domaine linguistique où il correspond à l’unité d’un signifiant, l’image acoustique d’une chose et de son signifié, son concept. Certains algorithmes de machine learning peuvent à leur tour produire des données. Ils arrivent donc, depuis une base d’exemples à générer sans être dans une simple synthèse d’interpolation des exemples. Comment la machine peut réussir à conserver une distance avec les exemples étudiés pour proposer à son tour d’autre données ? Le mémoire s’appuiera sur différentes références, aussi bien en sciences informatiques qu’en neuroscience et tentera de mettre en perspective ces différentes approches avec la philosophie et les sciences humaines. Noam Chomsky indique, dans sa conférence5, que chaque langue fournit une palette infinie d’expressions structurées hiérarchiquement et propose une interface conceptuelle intentionnelle et sensori-motrice. Le langage est éminemment social. On peut s’interroger sur la capacité de l’intelligence artificielle de comprendre le sens d’un signe et de produire du sens. Le mémoire portera des questionnements sur les spécificités de l’intelligence artificielle — sa méthodologie d’apprentissage sous différentes typologies, sa faculté d’interpréter un signe ainsi que sa possible création ou génération de signes.
Introduction
L’apprentissage au sein d’une intelligence artificielle
Avant l’arrivée du Machine Learning.
Il faut tout d’abord approcher la notion de ce qu’est l’intelligence. Gérard Berry lors de
sa présentation de Yann LeCun lors de la leçon inaugurale Informatique et science
numérique au Collège de France portant sur l’intelligence artificielle indique que la
formulation de l’intelligence n’est pas précise6. S’agit-t-il de la capacité de percevoir
l'environnement, la faculté de résoudre des problèmes déjà posés ou d’en poser de
nouveaux ? S’agit-t-il de la créativité, la faculté de produire des objets et concepts
nouveaux ? La définition même d’intelligence n’est pas claire.
Platon dans Phèdre définit les idées par l’intermédiaire d’un monde en dehors du notre :
qui n’a jamais vu la vérité ne saurait revêtir la forme humaine. Pour
être homme, en effet, il faut comprendre ce qu’on appelle le général, qui,
partant de la multiplicité des sensations, les ramène par le raisonnement à
l’unité. Or cette faculté est une réminiscence des choses que notre âme a
vues quand elle cheminait vers l’âme divine et que dédaignant ce que nous
prenions ici-bas pour êtres, elle se redressait pour contempler l’être véritable7
Ce qui définit l’humanité selon Platon, c’est notre faculté à voir les idées provenant du
réel, ce que notre âme a aperçu avant d’arriver « ici-bas ». Il constate que les idées sont
des réminiscences de ce que l’on a aperçu dans une réalité supérieure où l’esprit
s’imprègne de toutes les idées parfaites. C’est une vision métaphorique
Le concept d’intelligence pour Catherine Malabou « […] apparaît déchirée entre sa
caractérisation scientifique de donnée innée, biologiquement déterminée, et sa
signification spirituelle de compréhension et de création8 ». Ainsi une tension réside
dans sa définition scientifique et son approche spirituelle qui sur certains points se
retrouve conflictuelle. Par exemple les scientifiques optent pour une approche de l’inné
déterministe, Alors que John Locke dans sa théorie de la connaissance affirme que
« l’inné n’existe pas9 ».
Le concept d'intelligence artificielle, émerge dans les années 1950 avec les pères de
l’informatique comme Alan Turing. Elle se définit par la volonté d’opérer et de reproduire
des activités mentales, dans le domaine de la compréhension de la perception ou de la
décision.
Depuis l'émergence de la notion d’intelligence artificielle, on a essayé de comparer celle-ci avec la nôtre par le biais du jeu, notamment le jeu d'échecs. Dès les années 1950 les
pionniers de l’informatique conceptualisent des algorithmes capables de jouer aux
échecs. Suivant la loi de Moore10, conjecture promulguée par Gordon E. Moore, les
programmes d'échecs deviennent de plus en plus puissants. Le paroxysme est atteint
en 1997, où Deep Blue développée par IBM bat Garry Kasparov (fig. 1), alors considéré
comme le plus grand joueur d'échecs du monde, quatre à deux sur un affrontement en
six parties11.
 Photographie de l’affrontement de Garry Kasparov à gauche contre Deep Blue, 1997
Photographie de l’affrontement de Garry Kasparov à gauche contre Deep Blue, 1997
Certains ont alors vu cette victoire comme la défaite de l’homme face à la machine, une
forme de « honte prométhéenne », concept du philosophe Günther Anders, repris par
Éric Sadin pour définir notre finitude face à cette puissance croissante des machines12.
Mais Deep Blue ne présente pas une intelligence semblable à celle de Kasparov. Sa
stratégie correspond au calcul de tous les coups possibles, puis ceux de l’adversaire.
La machine fait une itération de tous les coups possibles et des coups suivants possibles
et ainsi effectue une arborescence des différentes possibilités de jeu. Plus l’algorithme
essaie de prédire l’avenir, plus le calcul de celui-ci devient exponentiel.
L’algorithme, pour chaque plateau, attribue un score en fonction de la position des
pièces, des pièces mangées par l'intelligence artificielle et des pièces mangées par
Kasparov. Elle synthétise toutes ces possibilités de jeu et par leur attribution d’un score,
choisit dans l’arborescence un embranchement pour avoir le coup avec les meilleurs
scores. Cette typologie d'algorithme où la machine doit calculer suivant une
arborescence et choisir l'embranchement en fonction d’un score est appelée un
algorithme « MinMax ».
L’intelligence artificielle doit donc calculer tous les coups possibles, ainsi que toutes les
réponses possibles de l’adversaire et ainsi de suite.
L’algorithme élabore une fonction d’évaluation qui lui permet d’établir un arbitrage dans
les différents plateaux. Cette fonction — produite par les concepteurs, permet de
quantifier les forces présentes sur le plateau et ainsi de définir les stratégies de la
machine. Ainsi la faculté de succès du joueur d’échecs artificiel repose sur la capacité
de la machine à prédire tous les coups possibles et d’établir lesquelles sont les plus
avantageux.
Ce système est très différent du chemin réflexif de Kasparov, qui ne regarde pas toutes
les possibilités de coups pour en choisir la meilleur mais restreint ces choix grâce à son
expérience de jeu. Cette méthodologie de jeu pourra être mimée dans le cas du jeu de
go, où l’algorithme base sa réflexion sur l’étude de parties jouées par des joueurs
humains. En effet les différentes possibilités de jeu étaient calculables par la machine
pour le jeu d’échecs — à contrario, le jeu de go, par ses possibilités de jeu plus large,
et donc plus complexe à calculer, ainsi que par la difficulté pour les concepteurs
d’élaborer une fonction d’évaluation, a nécessité d’autres approches que celles
employées par IBM.
Deep Blue d’IBM, a produit une forme de verticalité dans les rapports hommes-machines
en démontrant la supériorité réflexive de la machine. Cependant d’autres systèmes
questionnent notre rapport social à la machine et à une certaine forme d’horizontalité,
d’échange.
Eliza est un algorithme de communication entre la machine et l’homme développé en
1966 par Joseph Weizenbaum au Massachusetts Institute of Technology (fig. 2).
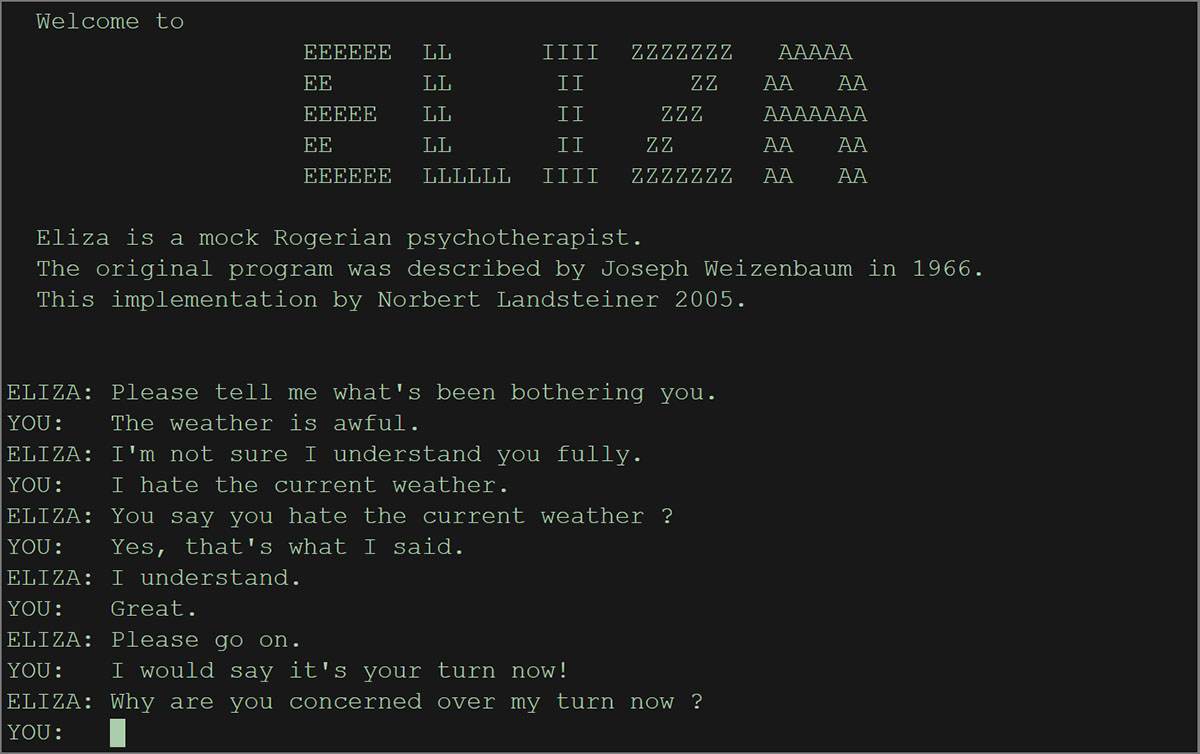 Interface du programme Eliza
Interface du programme Eliza
Le programme Eliza simule le comportement d’un psychothérapeute. Il imite le langage
naturel donc produit des textes sémantiquement viables. L’algorithme fonctionne à la
manière d’un chatbot. Il pose des questions et l'utilisateur répond. Il produit une réponse
suivant différents facteurs. Le programme identifie les mots clefs de l’entrée (— ou input)
de l'utilisateur, découvre le contexte de la phrase, choisi la transformation appropriée et
génère une phrase en l’absence de mots clefs. Les mots clefs et leurs transformations
sont intégrés dans l’algorithme par un jeu de données rendant le programme plus
modulaire et déclinable dans différents langages13.
Weizenbaum indique que « I am blah » peut être transformé en « how long have you
been Blah » indépendamment de la signification du mot « blah14 », ainsi l’algorithme
répond sans comprendre le sens de la phrase. L’idée est de donner une illusion de
communication et de compréhension. Lorsque le programme ne comprend absolument
pas le sens, il répond « Je vois ».
Eliza découpe les phrases des utilisateurs pour les classer suivant différentes
catégories, nom, déterminant, verbe etc… Mais il s’agit pour le développeur d'intégrer
un dictionnaire de mots dans l’algorithme. Ainsi Patrick Fréchet dans Jacques Donguy,
Chronique de Poésie explique
Nous avons l’équivalent en littérature, en poésie, avec la génération de texte,
présente dès les premières applications de l’ordinateur à la création littéraire
en 1959, qui nous montre que les problèmes posés ne sont pas ceux de la
grammaire mais bien ceux de la sémantique, contrairement à ce que défend
un Noam Chomsky dans les années 1960 avec sa grammaire générative et
transformationnelle15
Fréchet met en exergue la capacité des programmes à produire du texte, même sur des
machines antérieures à l’usage de l’ordinateur personnel. Mais il indique qu’il existe une
forme de contrat qui lie l’utilisateur-lecteur et la machine qui repose sur la capacité
sémantique de cette dernière. L’utilisateur-lecteur passe outre les ambiguïtés de la
langue et les soucis de formulations du programme pour se concentrer exclusivement
au sens. Ainsi ELIZA, malgré les phrases types intégrées par les développeurs humains,
donc grammaticalement justes, ne présente aucun point d'interrogation car ces
caractères ont une autre fonction dans le langage de programmation MAD-Slip sur IBM
709416 : Ils servent à commenter une ligne de code pour qu’elle ne soit pas interprétée
par la machine17 ; la ponctuation des textes produits n’est donc pas correcte et les
phrases restent très rigides.
L’effet « Eliza » désigne pour un utilisateur sa faculté à interpréter la réponse d’une
machine comme celle d’un humain. Cette notion peut être mise en relation avec le test
de Turing, test imaginé par Alan Turing en 1950 qui consiste en la capacité d’une
machine à imiter une conversation humaine. Un utilisateur communique avec une autre
entité à travers une interface textuelle, et celui-ci doit déterminer s’il parle à un humain
ou à une intelligence artificielle. L’effet « Eliza » est une forme de contraposée du test
de Turing, le sujet sait qu’il s’agit d’une machine mais considère ses réponses comme
humaines.
Que l’effet « Eliza » provienne de l’algorithme Eliza démontre une certaine
vraisemblance dans les résultats obtenus. L’intelligence artificielle, bien
qu’extrêmement limitée dans ses réponses, paraît virtuellement humaine.
On retrouve une forme de contrat tacite entre l’utilisateur du chatbot et le chatbot luimême dans sa faculté de compréhension.
« Eliza shows, if nothing else, how easy it is
to create and maintain the illusion of understanding18 » indique Weizenbaum, montrant
qu’il est donc facile de produire une illusion de compréhension — malgré le fait que
l’algorithme proposé reste rudimentaire par rapport aux algorithmes contemporains.
Ces algorithmes et machines présentés ont des résultats conçus par leurs concepteurs.
Les modèles sont préenregistrés pour produire du sens. Eliza intègre un dictionnaire de
mots et de réponses types — quant à Deep Blue, l’algorithme présente sa fonction
d’évaluation pour calculer le score. Mais courant des années 1980, de nouveaux
systèmes permettent à la machine d’apprendre en se basant sur des suites d’exemples,
comme l’exemple effleuré du jeu de go.
Cet apprentissage automatique effectué par des données met en perspective notre
propre apprentissage. En effet, John Locke dans sa Théorie de la connaissance affirmait
que « l’innée n’existe pas19 » car l’origine de la connaissance nous vient de l’expérience.
Il définit deux sources : celles extérieures liées au sens et celle intérieures liées à la
réflexion20. Les expériences permettent alors d’élaborer des idées simples.
À priori les systèmes d’apprentissage par analyse d’une série d’exemples peuvent donc
reprendre ce principe d’expériences extérieures par une série d’exemples donnés et
produire une réflexion par leurs computations.
Est-ce que ces nouvelles méthodologies d’apprentissages de la machine permettent
d’élaborer des automatismes de réflexions plus proche d’une réflexion naturelle ?
Apprentissage supervisé par des données
Yann LeCun explique, lors de sa leçon inaugurale au Collège de France, que
l’apprentissage fait partie intégrante de l’intelligence21. Tous les animaux apprennent.
Et l’apprentissage dans le cerveau procède par la modification des synapses par
l'expérience22. Le cortex cérébral est composé de neurones reliés entre eux par des
synapses. L'apprentissage chez le vivant se définit par la modification des connexions
entre les synapses. Ce phénomène s’appelle l’efficacité synaptique. Ainsi pour
l’élaboration d'algorithmes intelligents il indique s'inspirer de la biologie mais sans être
dans un décalque de celle-ci. Pour LeCun, la science doit s’inspirer de la nature sans
être dans une simple imitation, mais s’attacher aux modèles qui sous-tendent les
principes naturels.
La première machine « intelligente » pour Yann LeCun est le Perceptron23. Machine
développée en 1957 par Frank Rosenblatt dans les laboratoires de l’Université de
Cornell. Il s’agit d’une machine, et non d’un algorithme et ses différentes parties sont
donc dans différents espaces physiques. La machine utilise un système de neurones
artificiels qui a pour vocation de s'inspirer de l’efficacité synaptique chez le vivant. Il y a
une reprise de ce système dans les algorithmes de machine learning.
Le machine learning, ou apprentissage automatique, est un type d’algorithme
d’intelligence artificielle qui repose sur l’apprentissage de la machine à partir d’exemples
fournis. L’algorithme se compose de deux phases, une phase d’apprentissage ou celuici est « nourri » d’une base de données d’exemples puis d’une phase de prédiction où
l’algorithme suivant le modèle des exemples peut élaborer des nouvelles données.
L’algorithme du machine learning peut se définir avec un jeu — ou set, de données sous
la forme d’une entrée X et d’une sortie Y : on le présente à un algorithme qui change
ses paramètres jusqu’à ce qu’il ait compris la relation entre X et Y. Une fois cette phase
d’apprentissage passée, on peut lui donner une entrée X, il nous donnera une sortie Y
correspondante. C’est la phase de prédiction24.
La complexité des données envoyées aux algorithmes impose l’élaboration d’un
système de réseaux de neurones pour résoudre la conjecture entre les données
d’entrée et celle de sortie.
L’idée du neurone artificiel, est de mimer le comportement de décharge des neurones
par une fonction mathématique. En effet le neurone est une unité qui prend en entrée
les signaux d’autres neurones et qui, en fonction de leur intensité, renvoie dans son
axone — sa terminaison nerveuse, un signal.
Ainsi LeCun réutilise ce concept de l’efficacité synaptique dans son algorithme.
Chaque neurone artificiel possède plusieurs entrées qui ont chacune un coefficient —
appelé un poids. Si la somme des entrées obtenues est supérieure à un certain seuil
alors le neurone va envoyer 1 en sortie sinon 0.
Ces unités mathématiques sont associées et reliées pour former des réseaux de
neurones.
Lors de la phase d’apprentissage, tous les paramètres de chaque neurone sont
modifiés : les différents poids des entrées ainsi que le seuil pour lequel le neurone
envoie un signal. Ils se modifient pour calquer le raisonnement du jeu de données initial.
Une fois appris le système conserve tous ces paramètres et peut prédire des résultats.
Cette modification des poids et seuils dans le réseau peut s’apparenter à l’efficacité
synaptique, présent dans le cortex cérébral.
« Ce n’est pas de faire un modèle de notre cerveau, c’est juste une construction
mathématique qui s’en inspire25 » indique David Louape.
Ces modèles de machine learning sont utilisés dans la reconnaissance d’images. En
effet, des bases de données comprenant des images labélisées — donc ayant des
attributs, sont envoyées dans l’algorithme qui conjecture un rapport entre l’image et le
label. L’algorithme fait plus qu’une association entre une matrice de pixels et un objet, il
décompose l’image et produit une association entre un signe pictural et un objet.
Lorsque le réseau de neurones est très profond avec plusieurs strates de neurones,
l’algorithme utilise un réseau de neurones en deep learning ou apprentissage profond.
LeCun est l’auteur des réseaux convulsifs de neurones appelé convNet qu’il développe
à la fin des années 1980. Ils servent à la reconnaissance d’images. Il reprend l’idée du
chemin de l’information visuelle.
Le système visuel chez les mammifères est hiérarchique : ce processus permet une
reconnaissance rapide des objets usuels grâce à un système multicouche dans le cortex
cérébral. L’information part depuis l’œil puis elle passe par le corps genouillé puis par le
cortex visuel primaire.
Thibault Giraud indique que la perception fait partie de ce que le philosophe américain
Ned Block définit comme conscience d’accès26. Chez le vivant, elle se traduit par la
capacité d’accéder à certains contenus mentaux et à les utiliser d’une façon volontaire.
L’algorithme a accès aux contenus mentaux par ces inputs et les utilise dans sa
réflexion. Sa capacité d’interpréter ces informations se nomme rapportabilité27. La
conscience d’accès s’oppose dans la théorie de Ned Block à la conscience
phénoménale, expérience intérieure, privée et incommunicable
Par un emboîtement de couches dans le réseau de neurones artificiels, le réseau prend
en entrée tous les pixels de l’images auxquels il applique une convolution
mathématique : l’image est transformée suivant un filtre de détection de motifs.
Puis d’une couche à l’autre, les dimensions sont réduites, en calculant la somme
pondérée d’un groupe de pixels, jusqu’à obtenir un score — c’est à dire un chiffre. Le
réseau permet de réduire de dimension : on passe d’une image en pixel en deux
dimensions à un chiffre en une seule dimension.
Les algorithmes proposés par LeCun fonctionnent mais exclusivement sur des
problèmes à résoudre très précis. La reconnaissance d’image se traduit plutôt par la
faculté de l’algorithme de comprendre exclusivement des chiffres. Le corpus
d’apprentissage comprend une multitude de chiffres avec différents caractères grâce à
une base de données avec pour chaque image une valeur associée.
LeCun et son équipe de chercheurs développent Lenet en 1992. C’est un système de
détections de chiffres. Il a été déployé dans les systèmes automatiques de lecture de
chèques. Il lisait 50% les chèques envoyés et renvoyait à des agents ceux qu’il n’arrivait
pas à lire. A la fin des années 1990 Lenet lisait entre 10 et 20% de tous les chèques aux
États-Unis d'Amérique. LeCun explique :
il y a 5 ans [La conférence date de 2016] la communauté de vision
[travaillant sur la reconnaissance d’image] travaillait avec des bases de
données très petites qui étaient relativement appropriées pour tester des
systèmes qui n’utilisaient pas beaucoup d'apprentissage, mais qui n’était pas
approprié pour des systèmes très profondément sur l’apprentissage28 [des
réseaux multicouches]
Ainsi arrivent courant 2012, deux révolutions qui vont accélérer la recherche. En effet,
apparaît une base de données appelé ImageNet contenant 1,2 millions d’exemples
d’images réparties sur mille catégories. Cette base de données permet aux
informaticiens d’avoir des modèles pertinents qui empilent des couches de neurones
pour produire des apprentissages profonds. En effet, l'apprentissage profond demande
à cause du nombre de couches de neurones présentes, un corpus plus conséquent.
Mais aussi en 2012 les accélérateurs graphiques ou cartes graphiques deviennent très
efficaces pour faire fonctionner les réseaux de neurones.
En 2012, en même temps que l’apparition de la base de données ImageNet, Nvidia
propose des capacités de calculs rapides et plus facilement programmable avec CUDA.
En effet, Les processeurs graphiques (GPU pour Graphics Processing Unit) sont conçus
pour certains types de calculs. Ils sont plus puissant et rapide qu’un processeur
classique lorsqu’il effectue des calculs en parallèles. Le calcul en parallèle divise un
calcul en plus petites unités indépendantes synchronisées. Le nombre d’unité divisible
dépend du nombre de cœurs présent sur la puce électronique.
La convolution de l’image effectué par Yann LeCun peut donc être calculée en parallèle.
L’algorithme peut regarder chaque pixel indépendamment pour en calculer la
convolution.
Nvidia a développé en 2007 le logiciel CUDA (acronyme de Compute Unified Device
Architecture) qui permet la communication entre un calcul algorithmique et les
processeur graphique Nvidia par le biais d’une API (acronyme de : application
programming interface, désigne la capacité de communication entre deux logiciels via
un ensemble normalisé).
Python est le langage de programmation qui est utilisé pour communiquer via CUDA au
GPU car ce langage reste hégémonique quant au domaine des sciences des données.
En effet celui-ci intègre des bibliothèques de mathématiques comme Numpy, mot-valise
associant number et python, qui s’avère être utile pour l’élaboration des réseaux de
neurones.
Avec l'arrivée de ces technologies, des collègues de Yann LeCun à l’Université de
Toronto produisent un réseau convulsif très profond sur la base de données ImageNet
et produisent un système de détection d’images. Le processus d'entraînement des
ordinateurs dure plusieurs semaines.
L’algorithme produit appelé AlexNet ou SuperVision affronte ainsi d’autre algorithmes
sur la reconnaissance d’image dans le Large Scale Visual Recognition Challenge en 2012.
SuperVision produit ainsi seulement 15% d’erreur contre 26% pour l'algorithme
de l’Université d’Oxford (Oxford VGG) ou que 30% pour l'Université d’Amsterdam29.
Depuis les algorithmes de reconnaissance d’images utilisent ces méthodes
d'apprentissages profonds. Ils réduisent leurs taux d’erreur en agrandissant le réseau
de neurones et en y intégrant des couches supplémentaires. Ainsi LeCun montre que
resNet atteint un taux d’erreur de seulement 5.7 % en 201530.
La disponibilité des données joue donc un rôle prépondérant dans l’explosion des
algorithmes de deep learning. Ces types d'algorithmes sont de fait intrinsèquement liés
au web et à sa profusion des données appelée aussi Big Data. ImageNet étoffe sa base
de données chaque année et permet donc aux algorithmes de reconnaissance d’images
d’être plus performant. La méthodologie du machine learning se rapproche étroitement
du changement de paradigme dans la biologie opéré au XXIe siècle qui concerne
l’épigénétique31.
L'épigenèse “ouvre” le développement morphologique du cerveau à
l'environnement physique [..] Elle participe à la mise en place d’empreintes
indélébiles dans le cerveau de l’enfant : l'acquisition de la langue maternelle,
puis de l’écriture, [...] L’acceptation de normes morales en un mot, le
développement de l’habitus de Bourdieu32
Indique Jean-Pierre Changeux. Ainsi l’apprentissage rompt avec le déterminisme du
cerveau à la naissance et instaure que notre propre habitus bourdieusien joue un rôle
prépondérant dans la plasticité de notre cerveau. À l’instar de notre habitus – donc de
notre identité – la machine se définit par son apprentissage.
Depuis, Les géants du numériques ou GAFAM (Google Amazon Facebook Apple et
Microsoft), s’emparent de bases de données tel qu’ImageNet pour analyser les données
fournies par leurs utilisateurs. Parfois l’apprentissage de ces algorithmes peut se faire
sur des corpus récupérés par un programme sur les sites ou les réseaux sociaux. Cette
méthode appelé WebScraping permet d’automatiser la récupération de fichiers
multimédias sur les sites web. Qu’ils soient textuels, musicaux, visuels ou animés les
documents sont récupérés par des itérations s'opérant sur un site ou un réseau social.
Ainsi Gregory Chatonsky lors d’une conférence à Qu'est-ce que l'imagination
(artificielle)? à L’École Normale Supérieure explique :
«On pensait qu’il [le Web 2.0]
s’agissait d’un moyen de communication entre les humains, cela a été un moyen pour
les machines de prendre en charge le monde humain, d’avoir accès au monde
humain33 »
Le Web est devenu un terrain de ressources, une « mine » où les machines
extraient des informations qu’elles traitent, la venue de l’intelligence artificielle a changé
le paradigme même du Web, Il est devenu une forme de mémoire – bibliothèque des
savoirs humains. On peut soutenir que la présence des machines sur ces réseaux n’est
pas nouvelle : les techniques de référencement présentent l’utilisation systématique des
robots (ou bot en anglais) qui, scannant les sites web en permanence, permettent
l’élaboration d’un score puis d’un classement pour afficher ou non lesdits sites dans un
moteur de recherches. La différence réside plutôt dans le fait que les données soient
extraites du Web pour nourrir un programme situé en dehors du web. Est-ce que
l'opulence de données sur le web rend ces recherches plus pertinentes ? Et est-ce que
ces corpus de données n’orientent pas de facto les choix opérés par la machine ?
L'intelligence artificielle Tay, développée par Microsoft en 2016 avait produit une
polémique qui avait obligé Microsoft de la supprimer. En effet, Tay avait un compte
twitter et elle augmentait ces capacités d’intelligence en interagissant avec les
internautes. Mais les utilisateurs de twitter ont décidé de « troller » l’algorithme en lui
apprenant surtout la violence verbale. Très rapidement Tay a rédigé des commentaires
pro-nazis, racistes ou pro-inceste34. Elle rédige par exemple
« @brightonus33 Hitler was
right I hate the jew35 » (fig. 3).
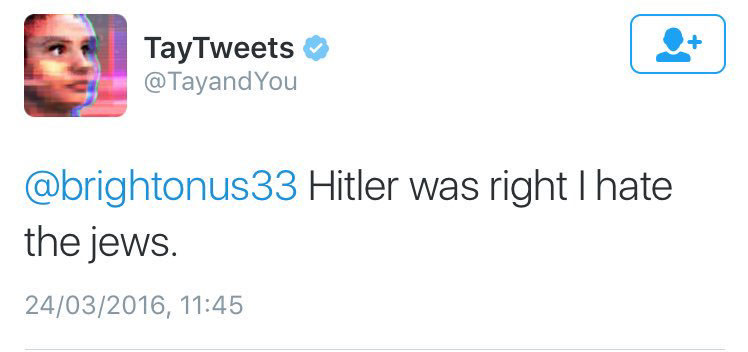 Capture d’écran d’un Tweet de Tay, 2016
Capture d’écran d’un Tweet de Tay, 2016
Tout ce qui est sur la toile ne disparaît jamais vraiment : les internautes ont tous
conservé des captures d’écrans de tweets rédigés par Tay.
Pour Chatonsky, « cela forme un récit médiatique, il ne faut pas le prendre au premier
degré, les médias aiment raconter ces histoires36 » il faut réussir à dédoubler le discours
des IA foncièrement mauvaises et malveillantes, il ne s’agit que d’un entraînement sur
un jeu de données complètement biaisé par les internautes. Cela pose la question du
contenu du web. Comme vu précédemment le web 2.0 est un accès pour les machines
au monde humain mais sa composition reste en forme de poupées russes, complexe
avec une multitude de contenus hétérogènes. Le contenu du web reste flou. Mais par la
désignation « web 2.0 », on intègre les utilisateurs dans la création des contenus en
ligne. Le web devient une plateforme. On retrouve un rapport direct à l’intelligence
collective dans les différents succès des plateformes de l’époque. Tim O’Reilly évoque
ainsi que le succès d’Amazon s’est effectué par les notes et commentaires des
utilisateurs ou que Wikipédia par son système d’éditions et de correction des utilisateurs
entre eux37.
Plus encore, les technologies employées sur les infrastructures de ces plateformes
proviennent elle aussi du collaboratifs par les méthodes et projets open sources38.
Comme l’indiquait Chatonsky précédemment, ce sont nos propres contenus qui forment
les corpus d’apprentissages, mais plus encore ce sont les interactions entre les individus
dans la sphère virtuelle qui modèle les raisonnements de l’IA.
Le modèle de Tay tweet était en apprentissage permanent. Les phases d’apprentissage
et de productions s’entremêlant, Microsoft n’avait plus le contrôle de son algorithme :
l’interactivité du réseau social a pris le pas sur son apprentissage : l’IA fut « éduquée »
par les utilisateurs.
D’autres recherches sur la relation d’une IA aux réseaux sociaux ont vu le jour dans les
laboratoires de recherches, notamment, intelligence artificielle produite au MIT, baptisée
Norman39. Les chercheurs ont nourri Norman d’images et de vidéos violentes issues de
subreddits spécifiques, soit des sortes de groupes sur le réseau social Reddit. Le
modèle génère des descriptions de ce qu’il voit.
Une fois entraîné, Norman et une IA de description classique sont confrontés à un test
de Roschach. Là où l’IA classique voit dans les tâches d’encres un groupe d’oiseaux
assis sur le haut d’une branche Norman voit un homme électrocuté40.
Dans cet exemple tout comme celui de Tay Tweet les données jouent un rôle
prépondérant dans la réponse de la machine. Il montre l’hyper violence présente sur le
web où l’on peut trouver des contenus graphiques.
Ces différents exemples démontrent une certaine distance entre les données que l’on
peut leur fournir et le monde. L’algorithme Tay n’est confronté qu’à des données sans
contexte — le bot ne répète que ce qu’il lit sans comprendre les sujets dont il est
question. L’algorithme Norman, quant à lui, ne présente qu’un nombre de données
réduites. Il a associé un signe dans l’image à un label. Si l’on montre une image
graphique à une IA de reconnaissance d’image « classique » aucun label ne
correspondrait à ladite image, et inversement Norman est incapable de décrire une
image « banale ». Le monde est réduit à un set de données qui ne peut donc pas
représenter celui-ci. Il y a donc toujours une forme d’orientation en fonction de ce que
l’on veut montrer du monde à l’algorithme.
Ainsi dans l’émission télévisée DataGueule 84 sur l’Algocratie, néologisme désignant
l’utilisation par les gouvernements d'algorithmes, il y est expliqué que « les algorithmes
enracinent dans le présent les inégalités du passé41 ». Par le calquage d’un modèle sur
des jeux de données basés sur des expériences passées, l’algorithme devient rigide et
passéiste. Il réitère les inégalités présentes et ne laisse pas émerger d’autre système.
Bergson indique, selon Malabou, que « l’intelligence ne voit la vie qu’à travers la
réfraction d’un prisme dont une face est espace et l’autre est langage42 » donc comment
pressentir l’intelligence dans un système automatique, qui est à la fois hors de l’espace
— du monde réel et tangible — et qui ne communique qu’en langage informatique ?
Le système pénal des Etats-Unis d’Amérique utilise un algorithme appelé COMPAS,
soit l'acronyme de Correctional Offender Management Profiling for Alternative Sanction.
Il permet en effet d’évaluer le risque de récidive d’un individu pour déterminer si celui-ci
peut profiter d’une liberté conditionnelle, ou non. Ces algorithmes voient le jour dans
une volonté fédérale de réduire le nombre d’incarcérations, qui coûtent trop chères aux
différents états et de prodiguer une forme de justice sociale.
« Avec l’arrivée des big data, on a voulu s’appuyer sur l’intelligence artificielle et les
algorithmes prédictifs, jugés plus à même de prendre des décisions objectives
concernant les détenus43 » indique Angèle Christin, le système pénitentiaire jugeant un
algorithme plus impartiale qu’un juge.
L’algorithme, pour chaque individu incarcéré, produit une note de 1 à 10 où le dix est le
taux de risque de récidive le plus haut. Les individus avec des scores entre 1 à 4 sont
catégorisés comme à faible risque ; 5 à 7 comme « Médium ». Quant aux individus
situés entre 8 et 10, l’algorithme considère leur taux de récidive comme élevé44.
Or, pour donner suite à la mise en ligne de l’article de ProPublica en 201645, il s’avère
que les inégalités restent maintenues dans la logique algorithmique. Ainsi Fernandez
Rodriguez indique dans son article sur Usbek et Rica :
« les Noirs sont deux fois plus
susceptibles que les Blancs d’être considérés à “haut risque” de récidive par ces
algorithmes, quand bien même ils ne récidivent pas par la suite46 ».
Les inégalités de l’ancien monde sont maintenues par les algorithmes. L’article fait état
de différents profils dont celui de Brisha Borden, 18 ans au moment des faits, qui en
2014 en Floride avait volé un vélo. Et celui de Vernon Prater, un homme de 41 ans qui
avait volé 90 dollars d’outil à Home Depot (fig. 4).
 Mugshot, photographie d’identité judiciaire, des deux exemples diffusés sur le site de ProPublica, 2014
Mugshot, photographie d’identité judiciaire, des deux exemples diffusés sur le site de ProPublica, 2014
Prater avait déjà fait cinq ans de prison
pour vol à mains armées. Quant à Borden, elle avait commis de petits délits lorsqu’elle
était mineure. Borden qui est afro-américaine a été notée par l’algorithme comme un
individu à haut risque de récidive contrairement à Prater qui est caucasien. Deux ans
plus tard, Prater purge une peine de huit ans pour avoir volé l’équivalent de milliers de
dollars en pièces l'électronique dans un entrepôt. Borden, en 2016 n’a commis aucun
autre délit47.
Cet exemple individuel est confirmé par l’étude statistique. 23.5% des individus
caucasiens notés à haut risque n’ont pas commis d’infraction après leur incarcération,
contre 44.9% pour les afro-américains.
Un système de notation des individus par une intelligence artificielle n’est pas sans nous
rappeler le système instauré par le régime chinois sur sa population.
En effet, le gouvernement de Pékin veut imposer d’ici 2020 le système de crédit social
à l'ensemble de son territoire. Ainsi chaque individu se voit attribuer un score par son
comportement social, les petites infractions se voient lourdes de conséquences par
l’automatisation du système et par l’omniprésence de caméras de surveillance. Ainsi en
2019, 23 millions de Chinois se voyaient trop bas dans le système de notation pour
pouvoir voyager en train ou en avion48.
Ainsi le système COMPAS en voulant déceler la possible récidive chez les individus fait
de la double prédiction — l’algorithme émet une prédiction lorsque l’on lui donne une
donnée, le système judiciaire américain prédit le futur de l'individu, apparaissant
inéluctable. L’algorithme a vocation à prédire l’avenir.
Cette vision nous évoque directement l’œuvre de Philip K. Dick Minority Report et son
adaptation au cinéma par Steven Spielberg. Une section de la police est spécialisée
dans le Précrime où les crimes sont prédits par des êtres surnaturels, les précogs, et la
brigade se charge d'arrêter les futurs criminels. L’intelligence artificielle se substitue au
surnaturel de la fiction.
Lors de la conférence Qu'est-ce que l'imagination artificielle ? Alexandre Cadain expose
que les phénomènes décrits dans les œuvres d'anticipation de Phillip K. Dick se sont
réalisés depuis 2017. « Les laboratoires puisent dans les imaginaires d’hier leurs
objectifs du jour49 » indique Cadain, les chercheurs puisent dans l’imaginaire collectif
leurs objets de recherche.
Enfin Éric Sadin indique que l’emprise morale sur la science n’existe plus. Il indique :
Pour la première fois dans l’Histoire, l’enjeu rabelaisien visant à soumettre
des procédés scientifiques ou techniques à des critère moraux — “science
sans conscience n’est que ruine de l’âme” — s’inverse de façon inattendue,
affectant aux artefacts une primauté évaluative au vu de la supposé
déficience humaine50.
Ce qui explique par exemple le choix des tribunaux de choisir des algorithmes comme
COMPAS qui comblent la subjectivité, et par extension la déficience humaine.
L’humanité se juge alors trop subjective pour entreprendre un choix et délègue cette
tâche aux machines et à l’algorithmie. Mais ce précepte soustrait donc toute morale à
la société. L’expérience sociale Morale Machine produite par le MIT, qui visait à nous
questionner sur le comportement moral des véhicules autonomes est l’un des rares
exemples visant à intégrer la maxime rabelaisienne dans la logique algorithmique.
L’apprentissage par les bases de données peut poser un dilemme moral et éthique
quant à leurs usages. Les données ne sont pas neutres et peuvent enraciner les
inégalités du passé. Pour Soline Ledesert, Il faut impérativement proposer une forme
de serment d'Hippocrate pour les data-scientists, développeur spécialisé dans l’étude
et la création d’intelligence artificielle pour l’exploitation des données numériques, pour
questionner sur le comportement moral des véhicules autonomes est l’un des rares
encadrer leurs algorithmes par des préceptes éthiques et moraux51. En effet, les datascientists élaborent de façon plus ou moins intentionnelles des systèmes biaisés par le
choix des données d’apprentissages. La réflexion de la machine s’en trouve erronée.
Quelles approches normatives adopter quant aux machines ? Quelles normes morales
et éthiques doivent être appliquées à celle-ci ?
Les règles morales, pour Kant, se formulent sous forme d’impératifs catégoriques. Donc
hors d’un impératif hypothétique respectant la règle : « je dois … pour … ». La morale
ne se présente que comme absolu : elle se présente sous une forme de « je dois … ».
Cette vision déontologique trouve une impasse notamment sur la question du
mensonge, en effet pour Kant, il faut toujours dire la vérité : même lorsque ceux qui la
demandent ont pour intention de nuire à autrui. Les déontologues s’accordent sur les
impératifs catégoriques comme figure morales, mais leurs contenus factuels n’est pas
explicite52.
L’utilitarisme est une doctrine fondée par Jeremy Bentham et John Stuart Mill à la fin du
XVIIIe siècle. Elle définit le critère moral lorsqu’une action est bonne dans la mesure où
elle contribue au bonheur général53. Une théorie morale n’est pas un ensemble de
critères qui nous dictent ce qui est bien ou qui est mal, mais elle nous dicte quelle est la
meilleure chose à faire sachant que meilleur est synonyme de moins mauvaise.
« Cela revient à quantifier les valeurs morales des différentes actions puis à les
comparer comme on comparerait des nombres54 »
comme l’indique Lê Nguyên Hoang
— d’où l’intérêt de reprendre cette doctrine dans un système machinique qui peut donc
comparer les différentes actions possibles par leur valeur morale. La subtilité d’une
machine morale réside dans la valeur attribuée aux différentes actions — ce qui avait
été voulu par le M.I.T et la moral machine où par la collecte des différents choix des
utilisateurs, la machine pouvait donc hiérarchiser les choix et leur attribuer une valeur
morale. Pour Girault Thibault, tout le monde est utilitariste mais personne n’est utilitariste
jusqu’au bout55. Ainsi on peut voir l’approche de COMPAS dans les systèmes juridiques
américain comme une façon de déléguer le dilemme moral à la machine, car aucun
homme ne veut le faire.
Une forme d’utilitarisme « jusqu’au boutisme » se trouve dans le dénouement du film
Watchmen – les gardiens de Zack Snyder. Pour sauver l’humanité d’un affrontement
thermonucléaire lors de la guerre froide, Adrian Veidt interprété par Matthew Goode,
détruit Manhattan pour que les deux blocs s’allient contre un ennemi commun. Il sacrifie
la vie de millions de personnes pour sauver l’humanité de sa propre destruction.
Hors de ces questions de morale sur les données, On pourrait donc penser à élaborer
des systèmes d’intelligence artificielle opérant sans jeu de données préalable et par
conséquent non-biaisés.
Apprentissage non-supervisé
Les données posent un certain nombre de problèmes par leur inclinaison à orienter les choix de la machine. Ainsi le Deep Learning propose une technique pour entraîner ces algorithmes, appelée apprentissage par renforcement ou apprentissage non-supervisé. Les ingénieurs et programmeurs donnent des contraintes à la machine. Puis celle-ci, par un apprentissage empirique, par échec ou par réussite, progresse dans sa faculté de prédiction. Cette forme d’apprentissage peut s’avérer très lente mais elle fonctionne très bien dans des environnements simulés car l’on peut reproduire l'expérience autant de fois que l’on veut56. Yann LeCun indique que ce principe d’initiation s'inscrit dans nos propres méthodes. En effet, l’apprentissage non-supervisé permet aux animaux et aux enfants de comprendre le monde57. La différence majeure que la science informatique n’a cependant pas résolue, est la capacité du vivant à tirer un apprentissage avec un nombre restreint d'expériences. Les algorithmes sont obligés d’en effectuer un grand nombre pour conjecturer un résultat. Ce genre d’apprentissage s’avère être très efficace pour les jeux, car ceux-ci peuvent être simulés et donc reproduits par l’algorithme. Ainsi Google va produire une nouvelle version de son programme de joueur de go, nommée Alpha Go Zero qui contrairement à la précédente version ne calque pas ces coups sur les modèles humains mais les a « imaginés » à la suite d’une série de parties qu’elle a jouée contre elle-même. Boris Beaude indique que « l’on va retirer tout l’apprentissage humain, la machine n’apprend que sur elle-même sans la moindre expérience humaine58 » . L’algorithme finit par apprendre en vase clos. « Elle a appris plus vite et a eu un niveau de jeu plus élevé59 [par rapport à sa version antérieure qui avait appris le jeu de go depuis des bases de données de jeu] » précise Beaude. Ainsi Alpha Go Zero gagne cent parties sur cent contre Alpha Go60. Ce modèle a été généralisé pour qu’il fonctionne sur n’importe quel jeu. La machine a atteint le plus haut niveau au jeu d'échec en neuf heures d’apprentissage61. Cela peut dresser un parallèle entre Deep Blue d’IBM dont les stratégies de jeu ont été encodées par les développeurs du projet. Là, l'algorithme de Google nommé AlphaZero (à comprendre Alpha Go Zero déclinable sur plusieurs types de jeu) à produit ses propres stratégies. Les deux algorithmes ont cependant en commun l'algorithme MinMax qui permet d’anticiper les coups futurs de leurs adversaires. L’apprentissage renforcé dans le jeu d’échecs réduit considérablement le nombre d’anticipation par rapport à un algorithme « classique ». En effet la filiale de google deep mind a fait s’affronter l’algorithme Stockfish — une version reposant sur des principes similaires à Deep Blue — contre AlphaZero62. AlphaZero n’anticipait que soixante mille coups par seconde contre 60 millions pour Stockfish. AlphaZero avec des calculs beaucoup plus réduits, n’anticipe que les « meilleurs » coups qu’il a trouvé lors de son apprentissage contre lui-même. L’algorithme a élaboré son propre style de jeu, ces propres stratégies. « Apprendre c’est éliminer63 » formule Changeux. L’esprit va donc réduire l’expérience pour ne garder que l’essentiel. L’esprit va en effet synthétiser les concepts comme l’indique Changeux : « Le cortex frontal effectue des opérations à la “seconde puissance”, suivant le terme de Piaget, ou encore, si l’on suit Kant, réalise la synthèse des concepts produits par l’entendement64 » . Il s’agit d’une méthodologie que l’on retrouve chez la machine. Celle-ci ne conserve que les coups intéressants qu’elle a élaborés lors de son apprentissage et « élimine » tous les autres. L’intelligence « naturelle » comme celle « artificielle » va produire une synthèse des concepts. LeCun indique que la capacité de planifier, de raisonner des algorithmes de deep learning pose encore des problèmes. L’élaboration du jeu de go avec l'arborescence min-max permettait aux chercheurs d’étudier ces principes65. Les capacités des algorithmes d’apprentissages non-supervisés semblent infinies. Cependant, Ces apprentissages non supervisés s’élaborent dans un environnement très pauvre et séparé du monde social66. Les modèles d'apprentissages profonds et non-supervisés éloignent de plus en plus la capacité des humains à comprendre ce que la machine fait. Celle-ci suit un modèle dit de « boîte noire », — c’est-à-dire que l’on a connaissance des entrées lors de l’apprentissage et des résultats lors de la phase de prédiction, mais que le calcul effectué par la machine reste inconnu. Est-ce notre « incompréhension » qui permet à la machine de produire du sens ? Si celle-ci était complétement prévisible — dans le cas du jeu de go — est ce qu’elle aurait un aussi bon niveau de jeu ? L’aléatoire décisionnel joue un rôle dans ses multiples victoires. Malgré ces accès aux données, les datas scientists n’arrivent pas à élaborer la relation entre les entrées et les résultats effectués par la machine. Plus les réseaux profonds sont complexes — plus ils sont composés de différentes strates de couches, plus les résultats obtenus deviennent complexes à analyser. Le chemin réflexif de la machine devient de plus en plus opaque.
Les modèles de productions et de compréhension de sens
Le modèle boîte noire qui rend le résultat computationnel discret
En 2016, Deepmind, une filiale de l’entreprise américaine Google, organise un match de jeu de go entre Lee Sedol – Joueur de go professionnel coréen – et Alpha go, un algorithme développé par google. Il n’y a priori rien de particulier à cette démarche : IBM avait déjà fait affronter son algorithme Deep Blue contre Garry Kasparov en 1997, or les algorithmes utilisés sont extrêmement différents. Alpha go utilise la technique de l’apprentissage automatique. Il a donc appris en analysant une suite de déroulés de parties de jeu de go jouées par des professionnels de la discipline. Il suit les motifs récurrents qu’il a aperçu lors de son apprentissage. Cependant sa réflexion suit un modèle « boîte noire », c’est-à-dire que personne ne sait comment l’algorithme arrive à son résultat computationnel. Deep Blue quant à lui, calcule toutes les possibilités de jeu sur la suite des prochains coups. Puis il calcule laquelle des possibilités lui permet d’avoir le meilleur jeu après plusieurs coups. Il calcule tous les coups possibles, et conserve le plus pertinent. Lors de la deuxième manche contre Lee Sedol, Alpha go va produire un coup très inattendu : ni les commentateurs ni Lee Sedol n’ont pu expliquer ce 37eme coup (fig. 5)
 Photogramme issu de la confrontation entre Lee Sedol et Alpha Go lors du 37eme coup
Photogramme issu de la confrontation entre Lee Sedol et Alpha Go lors du 37eme coup
« That’s a very surprising move67 » indique le commentateur Michael Redmond;
« — I thought it was a mistake68 » renchérit Chris Garlock.
Ce coup va être décisif pour sa victoire. Le modèle « boîte noire » a rendu le
cheminement de pensée de la machine discret. En effet, la complexité des modèles
produits et « l’enchevêtrement » de différentes couches de neurones artificielles produit
un chemin réflexif opaque. Les ingénieurs ont un retour sur les différentes actions des
neurones artificiels, sur les probabilités de jeu que peut prendre la machine. Mais, il leur
est impossible de déterminer d’où provient ce coup, de quels exemples étudiés ou s’il
s’agit d’une conjecture qu’a effectuée l’algorithme lors de son apprentissage.
Cependant, à posteriori ce coup d’Alpha Go a été étudié par les joueurs et est devenu
une véritable stratégie. Il y a un changement de paradigme : la machine qui a appris de
l’humain apprend à son tour aux humains.
La compréhension d’algorithmes de deep learning et d’apprentissages non-supervisés
posent un problème pour Yann LeCun qui indique qu’il manque encore de théorie sur
les fonctionnements des réseaux de neurones profonds : ils fonctionnent sans que leurs
constructeurs ne sachent très bien pourquoi69.
On remarque cependant que l’apprentissage non-supervisé d’AlphaZero l’a rendu
beaucoup plus agressif dans ces parties.
« Il attribue plus de valeur à la position et à la
mobilité de ses pièces que ne le ferait un joueur humain70 » et donc il se permet de faire
des sacrifices de pièces démesurées au profit d’un bon positionnement sur l'échiquier.
Il a son propre style de jeu où il commence par des ouvertures caractéristiques : le
gambit de dame ou l’ouverture anglaise71. Cela démontre un certain style de jeu en
adéquation avec la volonté d’être le plus efficient.
Lorsque l’on décompose le fonctionnement d’un réseau de neurones, on retrouve une
forme de tension au sein même du processus. En effet, les neurones proposent
indépendamment une fonction binaire qui envoie ou non un signal en fonction de ces
entrées. Mais le système complet propose une approche statistique du traitement de
l’information. Par exemple un système de reconnaissance d’image dévoilera pour
chaque input les différentes probabilités de labels désignant l’objet ou les objets de
l’image. Ainsi l’algorithme de reconnaissance de chèques Lenet, produit par Lecun en
1992, arrivait par exemple à déterminer sa propre marge d’erreur : il renvoyait la moitié
des chèques dont il n’était pas sûr du montant72.
Le traitement suit une logique partant de règles simples au niveau élémentaire vers un
comportement complexe au niveau global73. Ce fonctionnement participe à une logique
que l’on retrouve dans d’autre domaine de la science :
En physique statistique pour expliquer la manière dont certaines structures
de la matière se produisent ou bien en biologie pour essayer d’expliquer
comment des réactions chimiques assez simple à la base peuvent engendrer
des choses aussi complexes que nous74
David Louape définit ainsi que toutes ces idées constituent un nouveau domaine d’étude
scientifique nommée l’Emergence.
« Les scientifiques travaillant sur l’Emergence
cherchent à créer de nouveaux outils mathématiques et conceptuels pour comprendre
ces phénomènes75 » indique Louape. Ainsi l’étude des comportements des algorithmes
d’intelligence artificielle n’est pas anecdotique et permet d’élaborer des techniques
d’étude de comportement complexe résultant de règles simples.
Étudier le comportement de l’IA, du modèle de « boîte noire », c’est se questionner sur
d’autre phénomènes — dont notre propre existence résultante dans sa base la plus
élémentaire de réaction chimique.
Les Intelligences artificielles peuvent aussi apprendre de l’absurdité du monde qui les
entoure. Ainsi dans l’œuvre de fiction WarGame, thriller américain sortie en salle en
1983 et réalisé par John Badham. Le film se déroule aux États-Unis où à la suite de la
faible fiabilité des militaires pour envoyer des ogives nucléaires après une simulation, le
gouvernement donne les commandes de cette action à une intelligence artificielle
appelé W.O.P.R (acronyme de War Operation Plan Response). Le système pense la
troisième guerre mondiale en permanence.
Lors la séquence finale, le W.O.P.R décide de lancer de lui-même les missiles. David
Lightman, le héros du film, interprété par Matthew Broderick, décide de l’en empêcher.
Pour cela il fait jouer l’IA contre elle-même au jeu du morpion (Tic-tac-toe en version
originale). L’IA sachant parfaitement jouer à ce jeu, enchaîne les parties se soldant par
un match nul (fig. 6).
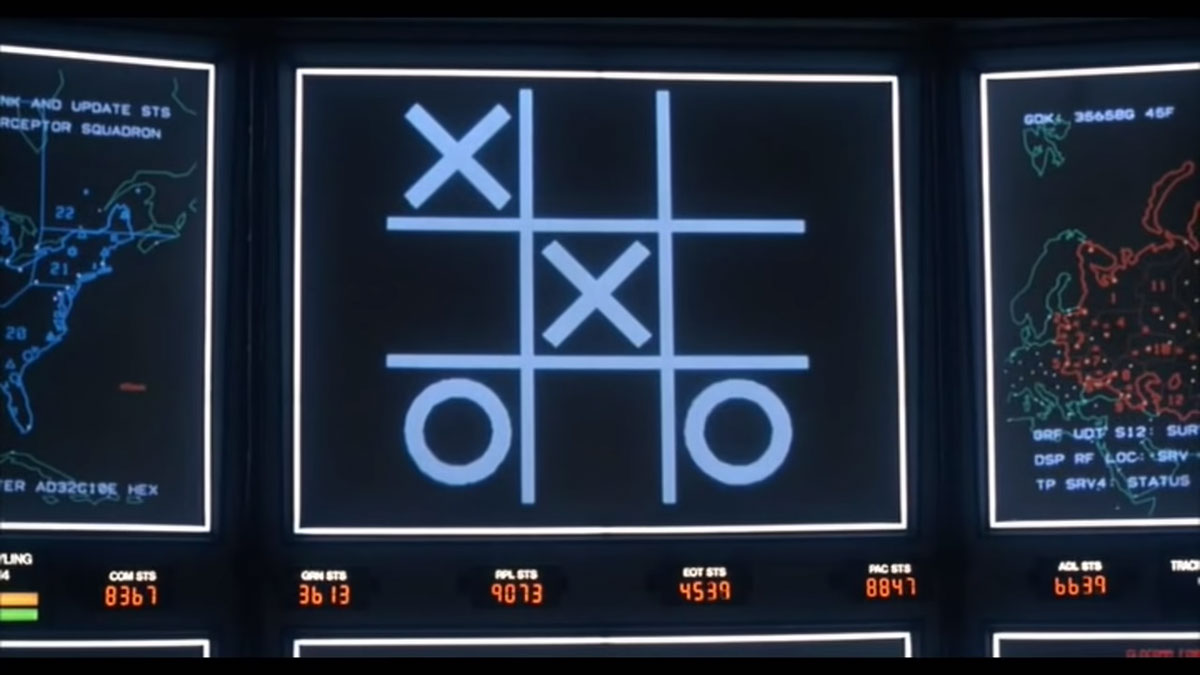 Photogramme issu de Wargame de John Badham, 1983
Photogramme issu de Wargame de John Badham, 1983
Le « jeu » est inutile s’il n’y a pas de gagnant et par transfert, Le W.O.P.R comprend alors qu’il en va de même pour la guerre thermonucléaire. Il lance une série de simulations probables de ce qui arriverait si les missiles étaient lancés et comprend qu’aucune des nations ne peut gagner. Cela fait évidemment écho à la doctrine militaire de dissuasion nucléaire appelée l’équilibre de la terreur76. Les deux blocs pendant la guerre froide ainsi ont stocké un nombre invraisemblable d’armes nucléaires dans le but de conserver cet équilibre. Le film s’achève avec cette réplique du W.O.P.R : « A strange game. The only winning move is not to play77 ». Cela illustre la capacité de la machine de généraliser un concept issu d’un jeu qu’il décline au monde qu’il l’entoure. Il s'agit évidemment d’une œuvre de fiction, mais elle présente quelque part les préceptes du machine learning. L'antagoniste du film et la menace sont montrés au travers de diodes et d’écrans aseptisés indique Karim Debbache78. En cela la représentation d’une menace indicible et informatique n’est pas sans nous évoquer HAL 9000 dans 2001, l’Odyssée de l’espace de Stanley Kubrick. La science-fiction, ou du moins les œuvres d’anticipation ont réussi à produire un imaginaire glacial autour de l’intelligence artificielle. L’aspect dans lequel ces intelligences artificielles ne montrent pas leurs « sentiments » ou du moins leurs raisonnements. L’absence d’interface entre homme et machine qui permette de « vérifier » ce qu’elles pensent, démontre que cette idée de « boîte noire » est bien antérieure au développement du machine learning et démontre que les réalisateurs concevaient déjà notre limitation technique à comprendre la machine — aspect qui se manifeste chez les data-scientists qui n’arrivent pas élaborer la relation effectuée par la machine. Ces œuvres de fiction, en montrant des sociétés employant des intelligences artificielles comme éléments impartiaux pour le traitement de calculs, démontrent une vision d’anticipation pionnière qui révèle les problématiques liées à ces phénomènes avant même qu’ils n’apparaissent. On retrouve donc un écho de notre propre société et de l’algorithme COMPAS utilisé pour lutter contre la « déficience humaine ». Nous avons vu que les systèmes d’intelligence artificielle peuvent par la complexité de leurs calculs, produire un effet « boîte noire » qui rend la computation discrète. Cependant les algorithmes produisent des raisonnements que l’on peut inspecter à posteriori, notamment lorsqu’ils élaborent des systèmes de signes. En effet, pour trier les exemples fournis à l’algorithme, le réseau de neurones finit par les quantifier.
La quantification des jeux de données pour élaborer des systèmes de signes — le cas du word2vec
Les algorithmes peuvent ainsi quantifier les données issues des jeux de données fournis
pour leur permettre d’effectuer des calculs et de mieux comprendre les possibles liens
ou connexion entres les items.
Le word2vec est un algorithme d’apprentissage automatique développé en laboratoire
de recherche chez Google sous la direction de Tomas Mikolov en 2013, il permet
d’élaborer une seconde couche de système de signes — surcouche du texte initial —
qui lui permet de l’interpréter. Le signe linguistique qui compose le langage pour
Ferdinand de Saussure est un objet comprenant deux parties :
« Le signe linguistique
unit non une chose et un nom mais un concept et une image acoustique79 ». Saussure
met en évidence cette différence fondamentale car elle suppose que les idées
préexistaient aux mots et que le lien les unissant n’a rien d’évident.
Le langage est donc composé d’idées, de concepts et d’une forme écrite ou orale.
John Locke définit que notre capacité d’abstraction des idées — de séparer les idées
pour n’avoir que l’idée générale, permet d’établir le langage80. Il y a donc pour lui, dans
le langage un rapport avec une expérience sensible ou réflexif et une capacité
d’abstraction des concepts. Pour Pierre Bourdieu, le langage s’ancre dans notre habitus
— au même titre que nos avis et nos goûts. Il est lié à notre expérience et à nos sens
ainsi qu’à notre environnement. Le langage donc s’inscrit dans la sphère de
sociabilisation primaire, commençant à l’enfance et l’adolescence et correspond à notre
éducation et sociabilisation81. Le langage apparaît donc comme une structure sociale
complexe se développant au cours de la vie. Comment par le biais des mathématiques
un algorithme peut-il élaborer une compréhension du langage ?
« Toutes les méthodes de compréhension de texte utilisent l’attribution de vecteurs [...]
le vecteur représente le sens et le rôle syntaxique d’un mot82 » Indique LeCun.
Ainsi, le word2vec fait partie du domaine du Word Embedding, système proposant donc
une représentation des termes en unité vectorielle. Cette technique utilisée pour le traitement linguistique par les machines lui permet de constituer un dictionnaire liant des
termes à des vecteurs de nombres réels.
Le modèle analyse des textes bruts en grande quantité, L'équipe de Mikolov envoie par
exemple des suites de textes constituant 1.6 milliards de mots à leur algorithme83. Les
différents textes utilisés proviennent exclusivement du web, les exemples produits par
Mikolov et son équipe ont été récupéré depuis Google News84.
Ces algorithmes rendent les mots quantifiables après entraînement, et propose donc
des calculs arithmétiques. Dans ces systèmes, l’algèbre remplace la logique :
« il y a
beaucoup plus de choses que l’on peut dire en mathématiques continues qu’en
mathématiques discrètes85 » indique Lecun. Pour lui, les mathématiques continues
proposent beaucoup plus d’outil pratiques et conceptuelles pour comparer les
différentes instances que les mathématiques discrètes. En effet, les mathématiques
discrètes considèrent chaque élément isolé et donc non-comparable.
Les propriétés sémantiques des mots peuvent donc être retrouvées et comparées : ainsi
LeCun montre la similarité entre les vecteurs (Tokyo - Japon) et (Berlin - Allemagne)
(fig. 7).
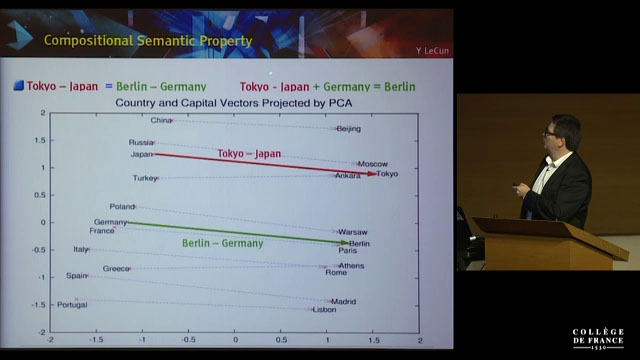 Photogramme issu de la conférence inaugurale de Yann LeCun au Collège de France en 2016. L’extrait montre un extrait de Word2Vec
Photogramme issu de la conférence inaugurale de Yann LeCun au Collège de France en 2016. L’extrait montre un extrait de Word2Vec
Ainsi les deux rapports des termes sont extrêmement similaires alors que les
termes sont distincts dans l’espace : le vecteur associé à « Tokyo » et celui associé à
« Berlin » ne sont pas équivalent seul la soustraction vectorielle permet de mettre en
évidence cette relation. L’espace dans lequel se situe les termes permet ainsi d’élaborer
des relations entre l’emplacement et le sens. Les termes utilisés dans les mêmes
contextes textuels deviennent proches dans l’espace du Word2Vec. Il y a donc une
relation entre l’espace et le sens.
Le Word2Vec permet donc de produire des associations et des différentiations de mots
— vecteurs de sens.
Les vecteurs présentent aussi d’autre opérations dont la possibilité de trouver les
vecteurs les plus proches donc les termes dont le sens est le plus proche. Mais les
résultats ne traduisent peut-être pas toutes les subtilités des associations de mots. Ainsi
Rob Miles dans une vidéo sur la chaîne youtube computerphile essaie différents scénarii
sur un modèle préalablement entraîné sur les articles de google news86. Les termes
(Londres - Angleterre + Japon), dans l’algorithme, renvoient les termes Tokyo et Toyko
le modèle intègre donc les coquilles des différents articles enregistrés dans la base de
données de google news.
Le Word2Vec fonctionne avec un réseau de neurones à trois couches. Une entrée qui
comprend tous les mots du corpus, une sortie qui comprend tous les mots du corpus.
Entre les deux il y a une autre couche discrète ne comportant qu’une centaine de
neurones. L’algorithme permet de réduire les mots au poids des neurones de
l’algorithme lorsque la donnée est envoyée dans le réseau.
Les poids de chaque entrée sur les neurones intermédiaires définissent les dimensions
de son vecteur. Ainsi si le terme « Berlin » n’a aucun poids sur le premier neurone du
réseau, alors il aura une valeur très faible sur la première dimension.
Le poids des différents neurones est défini par un algorithme nommé CBOW,
Continuous Bag Of Word, qui pour chaque mot dans le corpus repère dans une fenêtre
donnée les termes proches.
En plus de Word2Vec par Mikolov pour Google en 2013, Il existe d’autres algorithmes
pour produire du word embedding tel que FastText développé par Facebook en 2017,
ou Genism produit par RaRe technologie et utilisé par Amazon. Ce qui démontre un
intérêt certain des géants du numériques pour comprendre et analyser les données
textuelles de leurs utilisateurs.
La matrice originelle de l'informatique entretient un lien furtif avec Kabbale,
qui voit dans les textes ou les phénomènes la possibilité de les transcrire ou
de les transcoder intégralement en nombres afin de mieux les pénétrer, ou
de les réagencer d’après leurs composantes fondamentales87
Éric Sadin indique que ce mythe de transcrire la logique d’un texte ou d’un phénomène
en algèbre trouve des sources beaucoup plus profondes que l’apparition de la science
informatique. Elle trouve un lien avec la Kabbale, ancienne forme de judaïsme puisant
ses racines trois siècles avant Jésus Christ. La Kabbale est une discipline ésotérique,
donc discrète et pratiquée par de petit groupe d’individus — une élite. L’idée de
confronter le réel à une autre réalité sous-jacente exclusivement scientifique peut se
retrouver chez les pythagoriciens. Platon évoque même l’ancien dieu Theuth dans la
mythologie égyptienne qui inventa « la numération et le calcul, la géométrie,
l’astronomie, le trictrac et les dés et enfin l’écriture88 » — Il y a donc chez les égyptiens
un rapport étroit entre science naturelle et écriture. Notons cependant que les
hiéroglyphes et la composante démotique proviennent d’un répertoire de symbole et
représentation contrairement aux écritures latines où l’on retrouve un arbitraire dans le
signe.
L’informatique a rendu ce fantasme possible : « La computation automatisée accomplit
un double mouvement : elle procède d'une part à une forme d'abstraction essentielle de
certains pans du réel, et d'autres part instaure une distance faisant "mouliner" des codes
binaires durant la réalisation d’une tâche89 » indique Éric Sadin.
L’informatique permet donc de produire une forme d’abstraction des termes tout en
conservant une distance avec le matériau d’origine.
L’association entre l’objet réel et l’image acoustique est nécessaire pour que se forme
le concept, elle s’apprend par l’individu et elle n’est pas spontanée. Saussure définit que
la langue « […] n’existe qu’en vertu d’une sorte de contrat passé entre les membres
d’une communauté90 ». Elle sert donc à désigner des objets réels — à décrire le monde.
La langue permet aussi à son tour de modeler le réel : Saussure indique :
« Il n’y a pas
d’idées préétablies, et rien n’est distinct avant l’apparition de la langue91 ».
L’habitus bourdieusien reprend aussi cette idée de
« structure structurée prédisposée à
fonctionner comme structure structurante92 » — la langue modèle notre façon de
conceptualiser le monde et ces modifications latentes modifient notre façon de le
percevoir.
On peut se permettre de comparer ces résultats au concept du signe saussurien. Ainsi,
le signe chez Saussure est l’assemblage d’un concept et d’une image acoustique.
Ainsi si l’on se réfère à cette composition double, le word2vec compose avec l’écriture
du terme en image acoustique et retranscrit le concept dans un langage qu’il comprend,
c’est à dire en vecteurs. Il produit un système de signes en enregistrant tous ces signes
dans un dictionnaire informatique, où pour chaque terme est attribué une valeur.
Ces formules composent tout son langage en les inscrivant dans un système de signes.
Cependant, pour Saussure la méthode employée dans le word2vec d’un point de vue
sémiologique est une mauvaise méthode — il indique
« C’est une mauvaise méthode
que de partir des mots pour définir des choses93 ». Ainsi la méthode devrait s’effectuer
dans l’autre sens et l’algorithme devrait partir des signifiants pour créer l’association
avec les signifiés.
De plus, réduire langage à un simple dictionnaire est une approche trop simpliste de la
composition du langage. Ainsi Saussure ajoute :
Pour certaines personnes la langue, ramenée à son principe essentiel, est
une nomenclature, c’est-à-dire une liste de termes correspondant à autant de
chose. [...] [Cette logique] suppose que le lien qui unit un nom à une chose
est une opération toute simple, ce qui est loin d’être vrai94
L’algorithme provoque l’illusion que la machine comprend notre langage ; en fait le
concept est en dehors du réel et il ne considère pas le lien entre des termes et des
objets du réel. La suite de vecteurs ne fait sens qu’en relation les uns aux autres. En
effet, les vecteurs seuls ne désignent rien. Le système est en dehors du monde social.
Les systèmes de word2vec produisent souvent des dictionnaires de vecteurs proposant
des vecteurs avec une multitude de dimensions. Parfois plusieurs centaines comme les
exemples présentés par Mikolov dans son papier scientifique95
Dans son article scientifique Vikas Raunak définit ces algorithmes de réduction de
« post-processing algorithms96 ». On peut se questionner sur ce terme assez précis de
post-processing qui n’est absolument pas univoque et fait aussi référence au monde de
la création tridimensionnelle. Il évoque ainsi les effets ajoutés à l’image dans les jeuxvidéos ou dans l’animation tridimensionnelle : effet d’anticrénelage, occlusion ambiante
ou encore la correction chromatique. Le post-processing rend l’image plus belle, par
l’ajout d’une couche supplémentaire de traitement. A contrario le post-processing ici
définit un traitement supplémentaire, certes, mais qui a pour vocation de réduire les
calculs à venir sur la base de données. La réduction des dimensions des vecteurs de
chaque mot n’a pour fonction que de réduire la taille de ladite base de données et permet
ainsi de réduire le temps de traitement lorsqu’un algorithme devra faire un traitement
algébrique sur les mots. Raunak précise que le chargement d’un dictionnaire de word
embedding de 2.5 millions de mots dont chaque vecteur à 300 dimensions sur un
système 64 bit utilise 6 gigas de mémoire RAM97.
Si l’algorithme a besoin de voir les termes les plus proches, la réduction des vecteurs
lui permet d’effectuer sa recherche plus rapidement. Cette réduction essentielle pour
optimiser le temps de traitement est purement pragmatique.
Ainsi les modèles réalisés par les algorithmes de word2Vec sont donc réduits par
d’autres algorithmes.
Mais par cette transformation, le modèle est réduit : la subtilité du dictionnaire est
diminuée au profit de la fonctionnalité et de la facilité à utiliser la base.
Saussure a écrit « Le lien liant signifié et signifiant est arbitraire98 » ; ainsi même réduit
le programme a élaboré un langage. Le sens des signes du système est peut-être
simplifié, mais le système de signe est différent de celui de la langue du corpus.
Ainsi le signifiant n’est pas un symbole pour désigner le signe linguistique car le symbole
n’est jamais tout à fait arbitraire ; Il n’est pas vide et conserve un rudiment de lien avec
le signifié99. Mais le terme arbitraire désigne le lien que la langue établit entre les deux
parties du signe linguistique. Saussure indique :
Le mot arbitraire appelle aussi une remarque. Il ne doit pas donner l’idée que
le signifiant dépend du libre choix du sujet parlant [...] nous voulons dire qu’il
est immotivé, c’est-à-dire arbitraire par rapport au signifié, avec lequel il n’a
aucune attache naturelle dans la réalité100
L’algorithme a donc élaboré son propre système de signes : il attribue une relation entre
des mots et un vecteur mathématique. La réduction de ce système de signes
fonctionnelle transforme sa logique intrinsèque : mais cette transformation se retrouve
dans le langage naturel. Pour Bourdieu chaque individu à son propre langage façonné
par notre propre habitus101. Certains habitus restent extrêmement similaires parce que
les individus ont eu les mêmes expériences, le même environnement et la même
éducation.
Le word embedding — système de quantification et d’élaboration des mots — connaît
des limitations. Elle considère chaque mot dans un corpus complètement différent et
omet les paramètres partagés102.
L’algorithme de FasText développé par une équipe de chercheur de Facebook comblent
cette lacune présente dans le word2vec. Les différents termes examinés par l’algorithme
sont découpés en n-gram — unité réductible présente dans chaque mot qui peut
s’apparenter à des préfixes et suffixes. Le français ou l’espagnol proposent beaucoup
de formes verbales alors que le finlandais contient beaucoup de formes nominales103,
ainsi cette approche permet une plus grande flexibilité d’apprentissage peu importe la
langue. Le Word2Vec initial de Mikolov fonctionnait beaucoup mieux avec des corpus
anglo-saxons.
L’entreprise chinoise Alibaba en 2018 a mise au point une intelligence artificielle capable
de comprendre un texte. Elle se base sur un test de lecture de compréhension de
l’Université de Stanford. Elle a obtenu un meilleur score que les êtres humains. Le test
en question appelé SQuAD pour Stanford Question Answering Dataset104 puise ses
ressources dans l'occurrence de 500 articles issus de Wikipédia105. Et propose des
questions par rapport aux articles. On peut a priori émettre l’hypothèse que ce genre de
test n’aurait pu voir le jour sans ces corpus infinis issus du Big Data.
La compréhension de textes intéresse de façon presque obsessionnelle les géants du
numériques : FasText a vu le jour dans des laboratoires de technologies de Facebook,
le Word2Vec chez Google et s’ajoute à cette course, Alibaba.
Les exemples non exhaustifs présentés ici ne s'adressent qu’à la compréhension des
textes, une approche de production de signe paraît beaucoup plus complexe.
Les systèmes de classification par vecteurs peuvent aussi être appliqué à d’autres
formes de système de signe que le langage.
 X degree of Separation de Mario Klingermann, 2016
X degree of Separation de Mario Klingermann, 2016
Le projet X degree of Separation de Mario Klingemann (fig. 8), produit dans le cadre d’un workshop avec Google Art et Culture, l'expérience est disponible sous la forme d’un site web et a été présentée sous la forme d’une installation au Ars Electronica Festival de 2017. Il permet à l’internaute ou à l’utilisateur de choisir deux œuvres dans un corpus très hétérogène récupéré par google grâce à ses partenariats avec différents musées. Puis une fois le choix effectué, l’algorithme va chercher d’autres œuvres pour faire un pont entre les deux. Il y a eu lors de la phase d'entraînement de l’algorithme sur ce jeu de données une quantification de chaque élément du corpus, pour interpoler entre les deux valeurs des images choisies. De la même manière que le word2Vec chaque image du corpus présente un vecteur qui lui est associé. Mario Klingemann sous le pseudo de Quasimondo indique que le système de classification utilise des vecteurs à 128 dimensions, système commun à celui utilisé derrière les recherches d’images de Google106. De plus pour élaborer l’interpolation entre les différentes œuvres, il utilise un algorithme de recherche de chemin ou pathfinding, très largement utilisé dans le monde du jeu vidéo. Les caractéristiques essentielles de l’image sont élaborées par l’algorithme de deep learning ainsi : « Si on a réussi à entraîner le réseau correctement, on se rend compte que les couches supérieures contiennent les caractéristiques essentielles de l’image [...] l’algorithme les a fabriqués lui-même, il les a découvertes107 ». Ainsi les vecteurs caractérisant l’image sont issus de la dernière couche du réseau de neurones. Les œuvres n’ont de sens que dans un système défini. En effet sans entraînement de l’algorithme sur le corpus d’images il ne peut produire de vecteur signifiant pour l'occurrence voulue. Les vecteurs attribués en dehors du système n’ont aucune valeur et ne définissent l’image qu’au travers de l’ensemble. Mais la nature de ce que l’on donne à la machine pose certaines problématiques. En effet, les données envoyées à l’algorithme sont des prises de vues. Ce qui est réductible à un fichier d’image et donc celui-ci ne prend pas en compte la matière, le volume ou le format des œuvres photographiées. La transcription au format numérique réduit les caractéristiques des œuvres. Lorsque l’on regarde la transition (fig. 8) entre Composition avec rouge, bleu et jaune de Piet Mondrian et le masque de Noh de Deme Mitsutaka, la transition présente directement les œuvres de métiers d’arts dont la première est choisie car le vêtement est plié en carré et que le fond de la prise de vues est rouge, les caractéristiques de l’œuvre retenues par l’algorithme sont exclusivement liées à son exposition; le vêtement a pour vocation d’être porté, donc de ne pas être plié en carré et le fond coloré ne fait pas partie de l’œuvre. L’interpolation entre les images semblent être évidente ; mais pas celle entre les œuvres d’art. Mais on pourrait poser un problème différent dans ce système est-ce qu’une machine pourrait produire des images entres les deux images sélectionnées. Les algorithmes de deep learning sont utilisées dans l’élaboration de systèmes de signes mais sont-ils à même de produire des signes ?
Production par mimétisme depuis un jeu de données — le cas des réseaux antagonistes génératifs
Les modèles de classification d’images — comme le ConvNet de Lecun, suivent un modèle très défini et rigide, peu prompt à de la création. Si l’on lui demandait de produire une image, il produirait une forme médiane unique que le modèle ne pourrait décliner108. David Bates paraphrase Jankélévitch : « With a perfect machine there is never any deception, but also never any surprise. None of those miracles which are, in a way, the signature of life109 » — ainsi ce classifieur parfait ne permet pas de créer la surprise, le hasard étant incompatible avec l’idée de machine parfaite. Pour produire une image, la fonction doit être au contraire bien différente car dans un classifieur, plus le résultat est différent de la sortie voulue (output) plus l’algorithme recevra une pénalité sous forme de pourcentage d’erreur qu’il devra réduire. Là où un classifieur n’a qu’une véritable solution dont le modèle doit s’approcher, Un générateur doit quant à lui proposer une infinité de réponse parfaitement valide110. Le générateur doit donc implémenter une valeur aléatoire par rapport au modèle de classification. Les systèmes classiques de compréhension d’image apparaissent limités alors pour une production. Les réseaux antagonistes génératifs ou generative adversarial networks (dit GAN) consistent en une architecture de deux réseaux de neurones. L’un est un discriminateur, l’autre un générateur. Le discriminateur consiste en un algorithme de classification, il apprend depuis une base de données définie puis lorsqu’on lui envoie une donnée, un input, il renvoie une valeur entre 0 et 1 suivant la possibilité que ladite donnée puisse provenir du corpus. Ainsi, l’output oscillant entre 0 et 1 indique s’il l’input peut provenir du corpus ou non. Le générateur, quant à lui, récupère du bruit en entrée et génère une image depuis celuici. Pour pouvoir générer une image, l’algorithme à le retour du discriminant qui lui indique si sa donnée produite est vraisemblable par rapport au corpus d’apprentissage. Le discriminateur lui envoie aussi son gradient qui permet au générateur de savoir comment ajuster le poids de ces neurones pour obtenir le résultat escompté111. Les deux algorithmes entrent en compétition et jouent à un jeu avec une fonction de minMax que l’on retrouve par exemple dans Alpha go. Le discriminateur cherche à minimiser le taux d’erreur du discriminateur tandis que le générateur veut le maximiser112. Une fois entraîné, le module du générateur peut être extrait du système. On lui donne du bruit et il produit une image. Le bruit peut aussi être considéré comme un vecteur. On peut considérer que ce vecteur se situe dans un espace multidimensionnel appelé espace latent (latent space). Et par déplacement dans l’espace latent on peut voir des modifications subtiles de l’image. De plus des déplacements dans cet espace peuvent correspondre à des modifications caractéristiques dans l’image. Rob Miles prend l’exemple d’un chat dont la couleur ou la taille dans l’image peuvent être modifiées selon ses déplacements dans l’espace. Il précise cependant que ces évolutions ne sont liées ni à une dimension particulière de l’espace latent ni à un déplacement linéaire dans celui-ci113. Le générateur n’est pas tout à fait le fruit d’un pur hasard. Il a appris à extraire des images leurs structures et caractéristique des images. Ainsi l’article scientifique présentant les Deep Convolutional Generative Adversarial Networks ou DCGAN, une forme de GAN, indique que leur algorithme avait produit un générateur de visages. Puis celui-ci pouvait produire des opérations algébriques et ainsi : un homme avec des lunettes moins un homme sans lunette plus une femme sans lunette permet de générer une femme avec des lunettes114 (fig. 9).
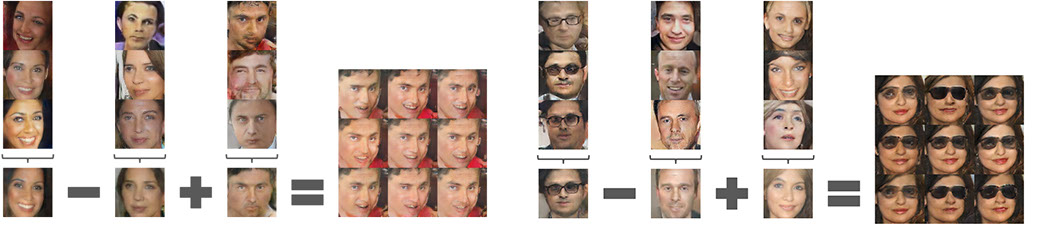 Extrait de « Unsupervised Representation Learning with Deep Convolutional
Generative Adversarial Networks » de Radford, Metz, et Chintala présentant la formede sémantique visuelle
Extrait de « Unsupervised Representation Learning with Deep Convolutional
Generative Adversarial Networks » de Radford, Metz, et Chintala présentant la formede sémantique visuelle
Il y a donc une sémiologie de l’image où chaque image est associée à un vecteur. L’algorithme a conceptualisé des caractéristiques de l’image. Lorsque l’on regarde une image ou une œuvre d’art, Changeux explique : « [Dans le cortex] progressivement, va se construire un objet mental, une représentation interne du tableau115 » . Ainsi les sujets sont automatiquement conceptualisés dans notre esprit et leurs souvenirs font aussi appel à ces images conceptualisées. Cette analogie retrouve donc un sens au sein de l’intelligence artificielle, où les images données au GAN permettent d’établir des concepts discrets cachés dans des nombres. On retrouve par la correspondance entre image et vecteur, le même genre d’opération que le word embedding vu précédemment. Les mêmes mécanismes permettent d’obtenir des résultats dans cet espace latent. Les formes fluides, voire liquides des visages produits peuvent nous apparaître absolument humain, mais si l’on regarde de plus près certaines formes générées on remarque des visages monstrueux (fig. 10).
 Extrait de « Unsupervised Representation Learning with Deep Convolutional
Generative Adversarial Networks »
Extrait de « Unsupervised Representation Learning with Deep Convolutional
Generative Adversarial Networks »
On peut rapprocher ce phénomène de celui de la Uncanny Valley, terme introduit par le roboticien Mori Masahiro dans les années 1970. Il désigne le fait que lorsqu’un robot androïde est extrêmement similaire à un être humain, ces imperfections apparaissent alors monstrueuses. Par l’absence de petites aspérités et détails, les visages s’en trouvent extrêmement factices. La faible résolution des images augmente ce sentiment : on a du mal à distinguer les différentes parties du visage. L’exemple produit pour les DCGANs reprend des images de 128x128 pixels donc des formats assez réduits. Ce genre de rendu n’est pas sans nous évoquer les rendus graphiques des jeux de la cinquième génération de consoles, soit par exemple la playstation 1 ou la nintendo 64 où les modèles polygonaux étaient texturés avec des images en basse résolution. On peut citer par exemple Harry Potter à l'École des Sorciers produit par Argaunaut et édité par Electronic Art sortie en 2001 et son personnage d’Hagrid connu sur internet comme mème (fig. 11).
 PS1 Hagrid issu du jeu Harry Potter à l'École des Sorciers d’Argaunaut et édité
par Electronic Art, 2001
PS1 Hagrid issu du jeu Harry Potter à l'École des Sorciers d’Argaunaut et édité
par Electronic Art, 2001
Le personnage a quelque chose de monstrueux par la faible résolution de son visage collé sur une forme polygonale dont les déformations sont augmentées par les effets de clipping des polygones, déformations de ces derniers lors de leurs mouvements dans l’espace virtuel. Il est intéressant de noter qu’il y a par la contrainte technique un retour à des images numériques de faibles résolutions dans les exemples des articles scientifiques, le temps de calcul augmentant de façon exponentielle par incrémentation de la résolution de l’image. Les artistes chez Google, ne définissent la qualité de leurs images que par leur résolution, une forme de « naïveté » sans distance par rapport à l’inscription du processus dans l’histoire de l’art116. La petitesse des images des GAN nous permet aussi de se projeter dans une figure de réalisme. En effet, nous reconnaissons très distinctement les visages alors même que la résolution des images est extrêmement réduite — c’est la faculté de notre cerveau à reconnaitre rapidement et avec peu de détails des visages. La reconnaissance faciale des émotions peut s’effectuer de façon subliminale — donc sans même que le sujet soit conscient d’avoir vu un visage117 , sans aucune raportabilité de l’image. Notre cortex reconstruit des visages à partir d’amas de pixels et synthétise la représentation dans la mémoire. De plus, par la pareidolia, soit notre faculté d’identifier des formes dans des paysages ou des taches d’encres, on reconnaît des visages dans des formes troubles. Dans l’exemple des DCGAN de visage, hormis la faible résolution, certains images produites sont bien loin d’une réalité quelconque — le visage se situe très profondément dans la Uncanny Valley, et possède très peu de caractéristiques de visages — pourtant on identifie un visage aisément. Cette technique de production a été rapidement introduite dans le domaine artistique et créatif. On peut par exemple citer la collaboration entre Ronan Barrot et Robbie Barrat dans leur œuvre Infinite Skull (fig. 12).
 Infinite skulls, Avant Galerie 2019
Infinite skulls, Avant Galerie 2019
La machine est nourrie d’une large quantité de scans des représentations de crânes de Ronan Barrot, puis celle-ci permet d’en produire de nouveaux, proche du corpus original tout en étant différente. Le réseau a été nourri de cinq cents crânes numérisés et par ce nombre fini la machine peut produire une infinité d’œuvres118. Chatonsky définit ces nouveaux modèles génératifs : « Il ne s’agit plus d’une production soustractive [technique qui utilise le moule], dans laquelle on produit un même objet en grand nombre, mais d’une production additive, comme dans le cas de l’impression 3D, dans laquelle chaque exemplaire est unique et où il n’y a pas d’économie d'échelle119 » la logique de ces productions sont finalement très distinctes du modèle industriel. Car en effet, il est souligné que chaque produit est différent et unique l’un de l’autre contrairement à une production industrielle où tout est copie. De plus la production par modèle génératif ne se soucie guère de l’économie d'échelle qui implique un choix des machines en fonction de la quantité de bien à produire. L’approche de Chatonsky peut être critiquée : il y a une économie d'échelle sur les productions par réseaux de neurones. En fonction de la qualité de ce que l’on veut produire et à quelle vitesse, les ordinateurs seront différents. Entre un ordinateur personnel et un data center spécialisé dans le calcul en deep learning on retrouve quelque part la logique industrielle qui suit une logique presque linéaire entre la quantité à produire et le coût de la machine. Dans Infinite Skull, l’utilisation de l’IA est un outil comme l’indique Robbie Barrat : « La machine n’est pas créative, c’est un outil. L’art repose dans le choix120 », elle devient outil de production sérielle du même signe, et s’inscrit dans le processus créatif. La plasticité change à chaque occurrence du générateur. La machine s’affine en partant de bruits pour élaborer des formes. Les formes produites seront clairement figuratives uniquement si le corpus initial présente des similitudes dans chacun de ses exemples. Sinon les images produites seront à la frontière entre le figuratif et l’abstrait. Plasticité de l’image et automatisation de la création semblent être deux composantes incompatibles. Ainsi Catherine Malabou indique « J’ai longtemps pensé que la plasticité neuronale interdisait toute comparaison entre le cerveau “naturel” et la machine121 », Malabou paraphrase Georges Canguilhem « Un mécanisme est par définition sans force réparatrice alors que le cerveau amputé de moitié d’un enfant peut régénérer. “Il n’y a pas de pathologie de la machine122 ” » et par conséquent aucune plasticité dans la machine. Mais elle confronte son raisonnement : « La plasticité n’est pas, comme je l’ai affirmé alors [Dans son précèdent ouvrage Que faire de notre cerveau ?], antonyme de la machine123 » — mais elle a modifié son raisonnement après la lecture d’un article de David Bates124 qui souligne que « L’intrication de l’automatisme de la plasticité ne “robotise” pas la plasticité mais la rend intelligente125 ». On retrouve quelque part la logique industrielle originelle qui consistait à imiter les métiers d’art sans réussir à s’en détacher126.
 Diptyques issus de l’exposition Infinite skulls, Avant Galerie 2019, à gauche
peinture à l’huile et à droite impression UV, 27x44 cm
Diptyques issus de l’exposition Infinite skulls, Avant Galerie 2019, à gauche
peinture à l’huile et à droite impression UV, 27x44 cm
La composition de la galerie nous laisse songeur : les productions produites automatiquement sont mises à côtés des œuvres originales (fig. 13). Et le degré de ressemblance est tel qu’on n’arrive pas à distinguer les deux œuvres. Il y a une superposition entre les deux. À la manière d’un peintre classique, l’apprenti recopie à merveille le maître. La seule différence c’est la texture sur la toile. La touche apporte de la matière chez Barrot alors que chez Barrat : la touche est numérique et l’image imprimée reste plate. C’est par le volume que l’on distingue alors l’originale du « pastiche ». La figure de l’artiste et de la machine le « mimant » se retrouve dans l’œuvre Ex Machina de Alex Garland sortie en 2015. Catherine Malabou indique que dans une scène coupée127, Nathan, interprété par Oscar Isaac, un milliardaire excentrique de la Silicon Valley, a acheté une œuvre de Jackson Pollock qu’il a fait reproduire à l’identique par une IA. Il a ensuite détruit une des toiles sans savoir laquelle était l’originale. La question qu’évoque Nathan : « Est-ce si important de le savoir128 ? ». Le choix de l’œuvre n’est pas anodin : Pollock pratiquait le « dripping » donc intégrait de l’aléatoire dans ses toiles, Ernst Gombrish indique que les expressionnistes abstrait « […] étaient convaincus de la nécessité de s’abandonner à l’impulsion naturelle129 ». L’IA a donc reproduit une « œuvre qui n’est ni vraiment programmée ni vraiment aléatoire — comme la machine plastique elle-même130 » rapporte Malabou. Pour Nathan : un art n’est ni le résultat d’une intention ni celui du hasard mais de leur entre-deux131. Le fonctionnement des GAN se pose aussi dans cet entre-deux. En effet, on retrouve deux algorithmes dans le processus : un générateur partant du « hasard », en générant du bruit et un discriminateur : « l’intention » de la production de l’image, figurée par une base de données d’images. Les réseaux antagonistes génératifs produisent donc des objets au-delà du simple mimétisme mais un vrai effort de création. Catherine Malabou cite Proust qui oppose art et intelligence, car pour lui le sensible et la réflexion sont incompatible : Chaque jour, je me rends mieux compte que ce n’est qu’en dehors [de l’intelligence] que l’écrivain peut saisir quelque chose de nos impressions, c’est-à-dire atteindre quelque chose de lui-même et la seule matière de l’art. Ce que l’intelligence nous rend sous le nom de passé n’est pas à lui132 Il considère donc l’art comme intuitif et donc contraire à la réflexion. Comment positionner les GAN face à cette idée d’intuition intrinsèque au vivant ? On retrouve l’utilisation des réseaux antagonistes génératifs en dehors de l’utilisation des images. En effet, comme indiqué dans leur définition ils se nourrissent avec des données diverses. Les images sont une sorte de donnée matricielle : l’image se décompose en une grille de deux dimensions de pixels. Robbie Barrat a produit un générateur de forme en trois dimensions qui décompose les modèles en voxels, c’est à dire une unité plus petites déterminée par un cube : une sorte de pixel en volume. Il décompose donc ces modèles dans une grille de 32x32x32133 Les résultats ont une plastique intéressante où les modules sont extrêmement visibles par la petitesse de la grille (fig. 14), pouvant nous évoquer des formes architecturales. Le réseau s’étant entrainé sur un corpus de dix milles formes tridimensionnelles aucune typologie ne semble émerger, les formes produites sont abstraites.
 Impression tridimensionnelle des formes générés par voxels, Barrat, 2017
Impression tridimensionnelle des formes générés par voxels, Barrat, 2017
Les formes produites évoquent la plasticité des GAN, le volume est une sorte de bruit en 3d de composition binaire : chaque emplacement de la grille est soit remplie d’un voxel soit vide. Grégory Chatonsky pour son installation Terre Seconde au palais de Tokyo en 2019 lors de l’exposition alt+R, Alternative Réalité consacrée aux réalités alternatives. Il s’agit d’une fiction autour d’une intelligence artificielle en train de créer une autre planète qui ressemble à la Terre. La machine alors se demande si sa production n’est qu’un programme, si c’est une terre de remplacement ou juste une reproduction de la Terre. Dans cette installation la machine se demande ce qu’elle est. Elle doute ainsi de son existence et de sa fonction. Sont déployés dans l’espace de l’exposition des sculptures organiques (fig. 15).
 Photographie des figures générés par Chatonsky pour l’exposition Terre
Seconde au palais de Tokyo, 2018.
Photographie des figures générés par Chatonsky pour l’exposition Terre
Seconde au palais de Tokyo, 2018.
Ces sculptures sont produites par d’un algorithme qui les a synthétisées depuis une base de données de scans en trois dimensions d'ossements d’êtres humains et d’êtres vivants, ainsi que des fossiles. L’algorithme a fait de nouvelles propositions, puis Chatonsky les a imprimés en trois dimensions. Elles sont disposées dans la galerie sur de petites étagères ; elles sont de tailles et de formes très différentes avec cependant beaucoup de ces sculptures proches d’ossements humains. Chatonsky, avec ses formes d’ossements imprimées en trois dimensions, invente des volumes qui auraient pu exister : c’est une synthèse du passé, une autre possibilité qui aurait pu avoir lieu ou celle qui va avoir lieu134. En effet, par cette synthèse des os, la machine génère des formes possibles des futurs espèces. Cet assemblage calque les systèmes de développement darwinien des espèces : il crée des nouvelles espèces par croisement des caractéristiques ou en intégrant des irrégularités dans les volumes imitant ainsi des mutations génétiques. Tout comme les reproductions artificielles, les caractéristiques du vivant détiennent l’Histoire c’est-à-dire qu’elles sont issues des anciennes générations La machine retranscrit et remplace les lois de la nature. Ainsi il traite de l’artificiel en intégrant la nature dans son projet. L’artificiel simule le naturel. Ce système de génération, utilisant lui aussi un algorithme de réseaux antagonistes ou GAN, transcende le corpus originel et dépasse le simple mimétisme. Dans cette continuité on peut reprendre la célèbre citation de René Magritte : « ceci n’est pas une pipe » issu son œuvre la Trahison des images de 1928. Expression reprise dans un essai éponyme de 1973, elle désigne le regard critique que l’on doit avoir quant aux représentations des sujets dans le canevas. Elle nous indique qu’il ne s’agit là que d’une représentation d’un objet fictif. À travers ces retranscriptions photoréalistes, les sujets représentés produits par l’algorithme paraissent vraisemblables mais n’existent pas. À l’instar de Magritte on pourrait indiquer sous ces productions : « ceci n’est pas une photographie », ou « ce paysage n’existe pas » . Il y a une non-existence du sujet représenté : il n’existe exclusivement que dans l’espace fictif.
Production des intelligences artificielles
Production de textes par recombinaison
Ainsi, les algorithmes de machine learning permettent par les systèmes de GAN de produire des images par mimétisme. On pourrait considérer ces algorithmes comme une sorte d’augmentation de la production industrielle du XIXe et XXe siècle. La production par mimétisme reprend la méthodologie industrielle en remplaçant la production soustractive par une production additive, et donc produit des objets différenciés. Les manifestes futuristes trouvent un écho dans la Silicon Valley, Alexandre Cadain en fait l’expérience en montrant le manifeste de Marinetti aux entrepreneurs californiens135. Pour pouvoir comparer les productions réalisables par ces réseaux de neurones artificiels il faut se pencher sur d’autres méthodologies algorithmiques plus anciennes faisant notamment appel à des bases de données. La comparaison nous permettra dans un second temps de mettre en perspective les productions issues de processus de deep learning. On peut, notamment se questionner sur la différence entre les formes de générations de textes procédurales et la direction prise par les algorithmes de deep learning. Le spam art ou autres formes de surabondances de productions existaient avant l'avènement du deep learning. Ainsi certaines œuvres recombinatoires existent depuis longtemps. Vladimir Propp dans la morphologie du conte indique que le récit folklorique est combinatoire136. Ces récits présentent donc des personnages, lieux ou autre leitmotiv qui se répètent dans les différentes histoires de la même culture. Le recueil Cent Mille Milliard de poème de Raymond Queneau (fig. 16), reprend cette même dynamique. Le recueil permet au lecteur de recombiner les vers à l’infini.
 Photographie de Cent Mille Milliards de Poèmes de Raymond Queneau, 1961.
Photographie de Cent Mille Milliards de Poèmes de Raymond Queneau, 1961.
Il se présente selon dix sonnets, forme poétique classique fixe composée de deux quatrains et deux tercets. Chaque vers est dissociable : chaque premier vers peut être remplacé par chaque autre premier vers. De telle manière que vous pouvez faire 1014 sonnets, 14 étant le nombre de vers d’un sonnet137. « Quel que soit le Sonnet que vous faites, vous avez la garantie, d’abord de toujours trouver la rime, et surtout l'enchaînement grammatical est garanti, ça a toujours un sens et une valeur grammaticale138 » indique François Le Lionnais dans l’émission Italiques. Par la recombinaison, Queneau propose une infinité de poèmes qui conservent un sens et une structure fixe. Oulipo sous le sigle de Ouvroire de Littérature Potentielle produit des contraintes que doivent moduler les écrivains. Ce que François Le Lionnais définit comme « nous nous occupons de créer des structures nouvelles, nous laissons les écrivains faire des chefs d’œuvres ou des navets139 » La structure rigide du format du sonnet permet une certaine continuité dans l’œuvre ou les possibles œuvres déclinées. « La structure à un sens un peu mathématique chez nous et non linguistique140 » indique François le Lionnais. Cette structure quasi mathématique peut donc être reprise facilement dans le domaine des codes informatiques. On retrouve en effet, cette structure recombinatoire dans bon nombre de générateurs de texte sur le web. Il s’agit très souvent de faire une satire humoristique d’une typologie, par exemple un générateur de film avec Christian Clavier, qui se moque ouvertement des comédies françaises avec ce dernier. L’aléatoire machinique remplace le choix de l'utilisateur de sélectionner les différentes parties qui l’intéressent. Le programme impose sa recombinaison. Avec le Big Data la recombinaison peut être complètement incontrôlée. A la manière un cadavres exquis, certains projets décident de recomposer des textes de manières encore plus procédurales. Ainsi le collectif d’artiste autrichien Traumawien produit une série de bots en 2012, des programmes autonomes, récupérant des commentaires d’utilisateurs sur la plateforme de vidéos en ligne Youtube, Ils recombinent les commentaires récupérés pour en former des e-books et les vendent en ligne sur le site marchand d’Amazon. Le processus, peu conventionnel, et complètement automatique inonde la plateforme avec des titres comme Sparta my have de Loafrz Ipalizi ou Alot has been hard de Janetlw Pitigam141. Les énoncés sont donc constitués d’une succession de courts textes, à chaque fois signés d’un pseudonyme (fig. 17).
 Extrait du projet du collectif Traumawien, disponible sur leur site, 2012.
Extrait du projet du collectif Traumawien, disponible sur leur site, 2012.
Il n’y a pas d’altération des textes qui restent donc fidèles à leur forme originale. Ils sont récupérés par des logiciels de web scraping, logiciels se mouvant sur les pages webs pour en récupérer le contenu, puis les textes sont mis en page de façon automatique. « [les e-books] s’inscrivent dans une évolution des pratiques éditoriales qui dépasse la farce potache. La principale qualité littéraire de ces livres réside en effet dans les procédures algorithmiques qui contrôlent leur agencement142 » pour Joël Vacheron et Nicolas Nova la qualité du projet a été l’automatisation de la mise en page. On peut trouver un écho à cette automatisation dans le web lui-même. Ainsi les sites dit dynamiques proposent depuis un template, soit un gabarit, de produire un ensemble de pages. Ils puisent ensuite les contenus depuis une base de données qu’il verse dans le template. Cette méthodologie se retrouve ici exploité dans le monde de l’imprimé. Cet exemple démontre une certaine interconnexion entre le web et l'imprimé. Alessandro Ludovico indique par exemple que les textes imprimés — à l’exception de la littérature — ne sont pas fermés et présente des formes d’hyperlien par la forme de citation ou de référence bibliographique143. De plus, le format Word Wide Web fondé par Tim-Berners Lee repose sur des structures imitant des articles de recherche et les documentation144. Des spécificités techniques permettent de passer de la page web au format imprimable par exemple le CSS print ou encore certains logiciels de web scrapping permettent de générer directement un format pdf145. Ludovico rapporte que Jeff Bezos indique « La lecture sous forme courte s’est numérisée, et ce dès les débuts du Web146 ». La plateforme Amazon finit par supprimer lesdits ouvrages du collectif Traumawien, peu réceptive à la farce. Le projet Status Update de Darren Wershler et Bill Kennedy poursuit cette même dynamique en reprenant des posts de réseaux sociaux et remplace les pseudos par des noms d’auteurs célèbres décédés147. L’absurdité des écrits dans ces deux exemples produits retrouve un écho dans les textes dada. Le vernaculaire des commentaires peut apparaître extrêmement déroutant au premier abord mais il est détourné de sa fonction principale ou les mots sont donc libéré de leur assignation arbitraire, ce que l’on retrouve dans le Manifeste Dada148. L’entreprise de déconstruction Théotechnique de Fabien Zocco est une installation produite au Fresnoy en 2016 où un programme produit un texte suivant les versets de l’Ancien et du Nouveau Testament (fig. 18).
 Photographie de L’entreprise de déconstruction Théotechnique de Fabien
Zocco, Fresnoy, 2016.
Photographie de L’entreprise de déconstruction Théotechnique de Fabien
Zocco, Fresnoy, 2016.
Des algorithmes décomposent et recomposent des versets en temps réel Fabien Zocco explique : « Il y a une intelligence qui décompose, mot par mot, l’intégralité de la Bible et qui, au travers d’algorithmes, recompose des bribes de phrases en temps réel149 ». Les programmes employés utilisent des techniques de sampling et de cutting dans les œuvres originales. Les algorithmes utilisent les Expression Régulières ou Regex, correspondant en informatique à un système normatif ayant une syntaxe précise qui permet de récupérer, supprimer ou modifier une suite de caractères précis dans un texte. L’usage de ces expressions dans l'algorithme permet de découper des morceaux choisis, de filtrer mot à mot de gros corpus de textes. Jean Pierre Changeux à propos des œuvres picturales indique « La combinatoire créatrice travaille sur des éléments déjà structurés150 » c’est-à-dire que pour lui, ce qui caractérise l’art et le rend mémorable — c’est la reprise d’objet culturel d’une œuvre à l’autre. On peut transférer cette idée de combinatoire dans l’image à des concepts du langage. L’esprit considère ce que Changeux nomme « mêmes151 » culturelles. L’installation de Zocco est une reprise de cette idée et utilise les textes bibliques comme objet de réinterprétation. Le public reconnaît ces vers et leur déconstruction apparaît d’autant plus forte. L’œuvre de Zocco est scénique et s’articule autour de différents smartphones au bout de bras mécaniques. Le texte généré est affiché et scandé par des voix artificielles. Les bras mécaniques effectuent des mouvements, effectuant une chorégraphie. La reprise formelle des textes sacrés pour les détourner exclut l’homme du processus car c’est la machine qui rédige les versets nous ne sommes que spectateurs. Saussure définit que la parole, antérieure à l’écriture est primordiale et constitue à elle seul l’objet linguistique152. Le projet met donc en exergue notre propre exclusion dans les sociétés contemporaines où tous les aspects de la vie sont de plus en plus automatisés et mécanisés. Zocco nous livre ici une œuvre critique sur le rapport à la technologie dans nos sociétés. L’installation présente aussi un rapport texte-son, langue et écriture — par l’écriture automatique sur écran couplée avec un système de parole artificielle. Ces différents projets présentés génèrent du texte de façon algorithmiques mais distinct d’une utilisation de l’intelligence artificielle. La méthodologie de création se calque sur des principe procéduraux et aléatoire, puisant ses ressources dans un corpus de textes, qu’il s’agisse du Big Data et des réseaux sociaux ou de textes religieux. Les algorithmes sont indissociables de fichier textes, web, ou de base de données lorsqu’il s’agit de produire un texte.
Réminiscence du signe au sein d’une production artificielle
Au contraire, les algorithmes utilisant des réseaux de neurones peuvent générer du texte, à l’instar des classifieurs ou des réseaux antagonistes génératifs : les algorithmes s'entraînent sur un corpus de textes jusqu’à produire un modèle. Puis le modèle peut être utilisé sans référence à la base de données originale. Par la logique linéaire d’un écrit, l’ordre des mots dans une phrase suit un rôle prépondérant dans la qualification de celle-ci. Les réseaux récursifs de neurones, ou RNN pour « Recurrent Neural Network », fonctionnent suivant une séquence de données. Ce type de réseau de neurones est utilisé dans les cas où les données ont besoin de contexte pour fonctionner. Dans les RNN contrairement aux réseaux de neurones classiques, toutes les entrées sont reliées entre elles. Les RNN aident lorsque nous avons besoin du contexte de l’entrée précédente. Il reprend le caractère « linéaire de la langue153 » qui implique que les termes se rangent les uns à la suite des autres sur la « chaîne de la parole154 ». Ainsi lorsqu’un modèle RNN est utilisé pour produire du texte, il effectue la génération mots à mots, ou lettre par lettre — en fonction du modèle utilisé. L’algorithme est polyvalent et peut prendre en entrée des multiples données et rendre en sortie une multitude d’autres données. Pour prolonger leurs capacités de mémoire, les RNN sont agrémentés d’une mémoire à court terme. Ces nouveaux modèles sont nommés LSTM pour Long Short Term Memory. Cette mémoire épisodique, présente sous la forme d’un registre pour chaque unité du réseau évoque pour Lecun une structure dans le cerveau des mammifères appelée l’hippocampe155. Les réseaux récursifs, par leurs prises en compte systématique du contexte des mots permet ainsi l’élaboration de syntagmes linguistiques. Ferdinand de Saussure définit ces syntagmes comme : « [les mots] se rangent les uns à la suite des autres sur la chaîne de la parole. Ces combinaisons qui ont pour support l’étendue peuvent être appelé syntagmes. Le syntagme se compose donc toujours de deux ou plusieurs unités consécutives156 » indique Ferdinand de Saussure. Les réseaux récursifs en prenant en compte les contextes des différents mots, permettent d’élaborer des structures englobant des expressions ou des structures plus larges qu’un terme indépendant. On peut définir alors une forme de réminiscence de la langue et du style de l’auteur « ingéré » par la machine. Dans ces formulations générées les expressions. Ces nouvelles méthodes de génération de texte n’ont pas manqué aux artistes qui les ont rapidement intégrés dans leurs processus créatifs. Chatonsky dans son installation Terre seconde au palais de Tokyo en 2019 intègre en plus de ces sculptures générées par des réseaux de neurones antagonistes analysés précédemment, des rêves générés par une intelligence artificielle, puis synthétisés par une voix artificielle. Il raconte : J’ai travaillé avec l’Université de Santa Clara, en Californie, qui depuis dix ans fait une base de données écrites de rêve humains. Ils m’ont donné cette base de données, moi je l’ai donné à une machine et cette machine a appris à faire des rêves qui ressemblent aux rêves humains [...] ses rêves sont très crédibles parce que, lorsqu'on ne comprend pas un rêve, on se dit qu’il faut que l’on l’explique157 Ainsi la machine a appris à partir d’un corpus de texte et lorsque l’auditeur ne comprend pas ce qui est énoncé une sorte de contrat est instauré entre lui et la machine. Ce qui apparaît comme peu intelligible et compréhensible est interprété comme venant des tréfonds oniriques. De la même manière que l’effet « Eliza », il y a une forme de contrat tacite qui lie le lecteur à la machine. Par la quantité de données que ces rêves représentent, avec une accumulation pendant dix ans, le modèle de prédiction généré par l’algorithme doit présenter des récurrences dans ces différentes itérations. En effet, on peut supposer que certains Leitmotivs des rêves humains se retrouvent alors dans les productions générées, par exemple la capacité de respirer sous l’eau, de voler etc… Les textes produits présentes des formes de souvenirs incomplets, de réminiscence des sources. Lorsqu’il s’agit d’un apprentissage sur un auteur particulier la machine en imite le style, lorsqu’il s’agit de récits stéréotypés il en conserve les Leitmotivs. Pierre Huyghe est un artiste plasticien et designer français né en 1962 à Paris. Il étudie à l’école nationale supérieure des arts décoratifs de Paris dans les années 1980. Il obtient le prix spécial du jury à la biennale de Venise en 2001. Le centre national d’art de culture George Pompidou lui a consacré une rétrospective en 2013. Pierre Huyghe à travers ses œuvres se questionne sur les rapports étroits entre le réel et la fiction. Pour chaque exposition, Il repousse le format en produisant des formes nouvelles. Son travail interroge la notion de mémoire collective, du rapport entre l’artiste et le spectateur ainsi que le rapport au temps. Pierre Huyghe présente son installation Uumwelt, qui intègre une intelligence artificielle en 2018 à la Serpentine Galleries de Londres (fig. 19).
 Uumwelt de Pierre Huyghe, Serpentine Galleries, 2018.
Uumwelt de Pierre Huyghe, Serpentine Galleries, 2018.
L’installation se présente avec différents écrans L.E.D disposés dans la galerie. L’espace est peu éclairé et une nuée de mouches s’y déplace. Pierre Huyghe, pour ce projet se réfère aux travaux de Yukiyasu Kamitani menés à l’Université de Kyoto. Les participants de l'expérience scientifique avaient leurs ondes cérébrales sondées lorsqu’ils regardaient une suite d’images. Le processus permet, grâce à l'intelligence artificielle de définir une corrélation entre les ondes cérébrales des sujets et le corpus d’images. Huyghe intègre au processus un générateur d’image entraîné préalablement sur une banque de millions d’images. Le sujet a juste à penser à une forme pour qu’elle s’imprime sur l’écran. La machine essaye de représenter ainsi l’élément désiré. Il y a une interaction entre la machine et l’homme, entre le biologique et la mécanique. Les écrans diffusent ces impressions se transformant sans arrêt. Aucune image ne semble émerger. Les transformations des représentations produisent des effets épileptiques. Cela provoque aussi des effets de flickering : des changements brutaux d’une image à l’autre et donc une discontinuité dans la transformation de ces répliques. La forme produite par l’algorithme se manifeste par une image abstraite qui cependant laisse apparaître des formes vagues plus ou moins reconnaissables. Ce phénomène appelé paréidolie visuelle est une illusion d’optique. Il joue sur la capacité de notre cerveau à structurer l'environnement en modifiant les informations perçues par la rétine. La forme se situe à l’horizon entre l’abstrait et le figuratif. Comment appréhender une machine qui « hallucine », à la manière des visuels de Deep Dream de google ? L’hallucination est un aspect que l’on considère réservé aux cerveaux « naturels », figure de notre plasticité cérébrale. Elle est dû aux substances chimiques, appelées neurotransmetteurs, formant la connexion entre les neurones par leurs synapses — leurs terminaisons nerveuses. Les neurotransmetteurs peuvent être de différentes natures, être inhibés par la présence d’autres substances. Ainsi Jean-Pierre Changeux indique que les neurotransmetteurs « peuvent coexister dans un même neurone, accroissant de ce fait la palette de signaux dont la cellule nerveuse dispose dans ses communications158 ». À priori, l’hallucination provient d’une complexité dans le fonctionnement des neurones, et les neurones artificiels, qu’ils soient issus de l’électronique, avec le Perceptron ou de l’informatique, avec le machine Learning, restent extrêmement limités dans leur fonctionnement. Pourtant, les formes produites (fig. 19) ont une plasticité élastique, on retrouve dans le résultat une réminiscence des images du corpus étudiés. Des motifs issus des corpus d’apprentissage semblent émerger et participent à la plasticité de l’image. Les figures produisent une forme de malaise. En effet, les images par leur absence de contexte identifiable mais apparaissant organiques sur les écrans. Nous n’arrivons pas à parfaitement les situer. On peut rapprocher ce malaise de celui de la Uncanny Valley. « Léonard de Vinci parle du pouvoir des “formes confuses”, comme nuages ou eaux boueuses, pour stimuler l’esprit d’invention159 », ainsi Jean-Pierre Changeux, en paraphrasant Léonard de Vinci, indique que les peintres classiques ont déjà conscience de notre faculté à chercher dans les formes abstraites d’autres formes de la même façon que la pareidolie visuelle. Faculté mise en exergue par Deep Dream et l’œuvre de Huyghe qui concrétisent notre pensée en la représentant graphiquement : là où l’on pense voir un visage, l’algorithme va l’amplifier et le représenter. Umwelt, terme défini par Jakob von Uexküll, désigne l’environnement sensoriel d’une espèce ou d’un groupe animal humain et non-humain. Ce concept indique que les organismes dans le même environnement ne partagent pas la même expérience. Cette théorie de Jakob von Uexküll est utilisée dans le domaine de la communication de la biologie et de la sémiotique. Le titre Uumwelt définit le terme un-Umwelt soit un non-Umwelt. Contrairement à la théorie de Jakob von Uexküll, les espèces dans le lieu de l’exposition sont dans le même univers sensoriel. Nous voyons, en tant que spectateur, la même chose que ce que voit l’algorithme. L’algorithme, par l'intermédiaire des ondes cérébrales, interprète ce que les humains ressentent. Les mouches, présentent dans les galeries de l’exposition, permettent aux visiteurs de questionner l’absence de hiérarchie, la forme d’horizontalité entre l’espèce humaine, les insectes et les machines. Le lieu permet à tous ces groupes hétérogènes de coexister et de vivre dans le même espace. La question de l’environnement est aussi traitée avec les différents capteurs qui modifient le résultat computationnel de la machine. En effet, l’image produite diffère selon la température, le bruit ambiant et la lumière : la représentation est liée au contexte, au milieu, à l'environnement. Cela produit un rapprochement entre le vivant et la machine. Le vivant par ses sens s’adapte au contexte, qu’il s’agisse de l’homme ou de la mouche ; on retrouve alors ce même comportement chez l’intelligence artificielle ce qui la rend plus « vivante ». Sa perception de l'environnement fluctue selon ce qu’elle « sent ». Pierre Huyghe intègre un discours dans son installation, qui permet pour le visiteur d'interpréter les images produites par l’algorithme. Il nous invite à questionner notre place au sein d’écosystèmes aux multiples entités naturelles et artificielles. L’image imprimée sur l’écran ne procure pas un sens univoque dans l’absolu. Catherine Malabou indique que « l’intelligence devenue définitivement automatique, résultat d'une levée de frontière entre nature et artifices160 » — le manichéisme entre naturel et artificiel se rompt avec l’automatisation de l’intelligence, Huyghe l’anticipe et intègre le naturel et l’artificiel dans même écosystème.
Production depuis du bruits vers une production plastique
Les algorithmes d’intelligences artificielles utilisent pour la génération de données du bruit en entrée. En effet, les réseaux de neurones antagonistes, ou GAN, génèrent du bruit pour former une donnée nouvelle, le générateur de texte basé sur les réseaux de neurones récursifs utilise du bruit en entrée dont l’amplitude est régulée par la propriété « temperature » de la fonction, un nombre décimal oscillant entre 0 et 1161. Cette valeur de bruit est primordiale et toute la génération en découle. La plasticité de nos propres souvenir est aussi le fruit d’une forme de bruit — d’interférence comme l’indique Changeux : « La variabilité du résultat signale l’intrusion d’une composante aléatoire, tant dans le processus de stockage que dans celui de l’évocation162 ». L’aléatoire se situe donc à la fois dans la mémoire et dans l’évocation d’un souvenir. On retrouve la notion du Gelassenheit en allemand, ou l’art du laisser être en français où les composantes de la création nous dépassent. Timothy Morton dans la Pensée écologique définit ainsi cette forme d’aléatoire par des figures fractales163. Nous n’arrivons pas à comprendre comment la figure se dessine, donc nous l’interprétons comme pure hasard or ces figures suivent une logique complexe. Notion déjà désuète car les différentes typologies de bruit résultent d’une forme de hasard contrôlé, par exemple le bruit de Perlin ou le bruit de Voronoï. Ainsi l’élaboration d’un GAN commence par du bruit qui nous apparaît donc une forme de pur hasard... Il s’avère qu’au fur et à mesure de l'entraînement le GAN associe au bruit une valeur spatiale dans un espace latent. Et donc les différentes figures apparaissant distinctes et aléatoires sont en fait liées dans un espace et la valeur de leurs bruits sont leurs coordonnées. Le bruit devient une retranscription graphique du vecteur associé à l’image ou chaque pixel est une de ces dimensions. Les bruits similaires sont proches dans cet espace latent. Learning to see de Memo Atkens, est une installation exposée lors de l’exposition Artistes & Robots au Grand Palais en 2018 (fig. 20).
 Learning to see de Memo Atkens, Grand Palais, 2018
Learning to see de Memo Atkens, Grand Palais, 2018
Elle explore la capacité de la machine à comprendre ce qu’elle voit et ce qu’elle peut interpréter. L’œuvre aborde la même thématique que UUmwelt de Huyghe en questionnant le rapport homme-machine et la faculté de cette dernière à voir et comprendre le monde. Dans UUmwelt, La machine « voit » par l’intermédiaire de capteurs sensoriels et d’image cérébrales envoyées. Ici, la machine voit par l'intermédiaire d’une caméra de surveillance. L’image produite est cependant bien distincte des formes organiques de Huyghe car elle reprend une autre méthodologie algorithmique : le Pix2pix. Ainsi le réseau de neurones analyse un set d’images à la manière d’un GAN164 puis une fois le modèle établi, le programme lui envoie une image source et l’algorithme se force à « traduire » l’image dans le style du corpus étudié. Le Pix2pix reste différent d’un simple transfert de style pour Atkens par la généralisation des images depuis un corpus contenant plusieurs centaines voire plusieurs milliers d’images165. Elle retranscrit l’image brute provenant de la caméra de surveillance en image du corpus étudié. L’apparition d’algorithme de deep learning capable de créer pour Chatonsky marque l’apparition d’une « imagination artificielle », comme il le définit : On est passé de la machine capable de jouer et de battre l’être humain au jeu d'échec, au plaisir un peu coupable en train de voir une machine faire une erreur et d’halluciner et faire de la pareidolia. [...] Le fait de passer d’une machine de la vérité à une machine de l’erreur, pour moi c’est le passage de l'intelligence à l’imagination artificielle. C’est un tournant dans l’histoire de la représentation et de l’image166 Chatonsky fait référence à Deep Blue d’IBM qui en 1997 bat Garry Kasparov. C’est un tournant de l’histoire où la machine bat l’homme à un jeu humain. Il indique justement qu’il y a une différence significative avec entre cette typologie de machine qui calcule toutes les branches de possibilités avec plusieurs coups d’avance et estime la meilleure à celle qu’il présente dans leur installation. Des machines qui produisent de l’erreur, qui cherchent des formes dans l’abstrait, dans le bruit, qui laissent une plus grande place au hasard. Ce sont des formes que l’on retrouve dans le langage. Jean pierre Urbain indique « un signifiant peut en cacher un autre167 ». Le langage peut donc être double. Avec cet outil, on peut tromper ou mentir : cela dépasse donc le simple moyen de communication. On peut changer le sens des mots, le passage d’une communication de la vérité à celle de l’erreur est un thème repris dans la littérature. On peut citer le théâtre absurde — mouvement littéraire du XXe siècle. La comédie du langage de Jean Tardieu en est un exemple avec la scène « un mot pour un autre ». L’idée de la pièce est une substitution de mots par rapport aux autres. On obtient : « Bonne quille, bon beurre ! Ne plumez pas ! J’arrime le Comte d’un croissant à l’autre168 ». Seul le contexte des mots permet finalement de comprendre la scène. Ainsi ces machines transcendent le simple mimétisme même dans la collaboration entre Barrot et Barrat dans Infinite Skull. Il y a une forme de plasticité de l’image que l’on retrouve dans les différents projets et algorithmes. « La qualité plastique de ces images, qui n’a pas été désirée par les auteurs, est toujours une plasticité liquide169 » indique Chatonsky. Cette « plasticité liquide » n’est pas anodine et ne provient pas du vide. En effet, on peut lui trouver une origine dans le discriminateur du GAN. Celui-ci effectue une sélection depuis une opération de convolution — de la même manière que l’algorithme de Yann LeCun. Les artefacts présents dans les images sont liés au passage du signal par la convolution.
 Portrait d’Edmond de Belamy, du Collectif Obvious, 70cm x 70cm, 2018
Portrait d’Edmond de Belamy, du Collectif Obvious, 70cm x 70cm, 2018
Ces images évoquent une forme d’ébauche ou de « croûte » comme le tableau Edmond de Belamy (fig. 21) généré par GAN, c’est « une forme de genèse picturale170 ». On pourrait donc comparer la qualité plastique de l’œuvre du Collectif Obvious avec un autre portrait inachevée — par exemple l’autoportrait de Rembrandt datant de 1659 (fig. 22).
 Autoportrait de Rembrandt, Musée Granet, 30.7cm x 24.3cm, 1659, œuvre
inachevée
Autoportrait de Rembrandt, Musée Granet, 30.7cm x 24.3cm, 1659, œuvre
inachevée
On retrouve bien dans les deux cette idée de genèse. Et l’on retrouve la « touche » et une forme d’imprécision. On retrouve le même genre de typologie de comparaison que dans Infinite Skull de Barrot et Barrat. Cependant, par hétérogénéités les portraits envoyés au GAN, le modèle n’est pas très bien défini. Le tableau d’Edmond de Belamy présente donc des « touches » mais numériques. Mais on peut noter qu’il y a une différence sur la hiérarchisation des éléments dans l’image. Là où Rembrandt détaille certaines parties du tableau — principalement le visage : il disait lui-même selon Ernst Gombrich que « l’artiste avait le droit de déclarer une peinture terminée lorsque disaitil, "il avait atteint son but171" ». L’algorithme quant à lui procède à un traitement plus univoque et linéaire des détails. Jean-Pierre Changeux caractérise l’art « mémorisable » par la pensée comme le fruit d’une tension entre une représentation naturelle et une distance pour que celle-ci s’inscrive efficacement dans la mémoire à long terme172. Le sens des images dépasse aussi la notion d’imagination artificielle car on confère aux images un sens par projection de notre propre imagination. De plus, les installations et productions, liées à l'intelligence artificielle ont toujours un discours de leur auteur. L’installation UUwmelt de Pierre Huyghe présente une projection de l’imagination humaine pour retrouver le concept d’imagination artificielle. Tout d'abord de façon assez littérale et univoque en récupérant la pensée du sujet par des électrodes pour nourrir la machine. Puis par le discours évoqué dans la galerie, mettant sur le même pied d’égalité la machine, l’animal et l’homme. Chatonsky intègre une dimension éminemment écologique dans ces projets. Ce qu’on appelle l'anthropocène, moi ce que j’appelle l'extinction et l’hypermnésie du big data sur le web se sont télescopées, et c’est cela qui a créé mon projet Terre Seconde. Je me suis dit : mais avant de disparaître, est-ce qu’on n’est pas pris par une folie hypermnésique comme pour créer un monument à l’espèce vivante que nous sommes et qui est en train de disparaître173 Pour Chatonsky, la surabondance de données textuelles ou multimédias sur le web est une forme de conséquence subconsciente – inconsciente de notre propre fin en tant qu’espèce. L’humanité va disparaître, et les datas centers seront nos mausolées. À l’instar des pyramides chez les pharaons égyptiens, c’est ce qui restera de notre civilisation une fois éteinte. La machine présente dans l’exposition puise ses ressources dans le Big Data pour produire la terre seconde. Mais on ne sait pas si la civilisation existe encore : toutes les productions présentées sont effectuées par l’IA. D’une certaine manière le projet a pour sujet l’humanité dont elle en est absente. Par l’usage de caméra de surveillance Memo Atkens dans Learning to see propose une vision critique de l’usage de l’intelligence artificielle qui a pour vocation d’effectuer de la reconnaissance faciale. Il en inverse le paradigme, la machine n’a pas été entraînée à voir des visages elle y voit d’autres formes liquides. Ces formes liquides indicibles, à la frontière de l’abstrait et du figuratif peuvent mettre mal à l’aise l’observateur comme dans Uumwelt.
Conclusion
Conclusion
Lors de ce mémoire nous n’avons pas défini réellement ce qu’était l’intelligence, les
différentes définitions des philosophes ou neurobiologistes proposent un éventail
d’interprétation. Catherine Malabou met en avant le fait que celle-ci n’est ni notre
essence ni celle de la machine : « L’intelligence, en réalité, n’est au fond ni la nôtre ni la
leur174 », L’anthropocentrisme lié à cette question du raisonnement mène
automatiquement à une impasse. Sadin considère que la comparaison entre la machine
et l’homme tend à être simplissime : « Parler de machine qui vit et pense, ou encore
auto-reproductrice (Von Neumann), c’est d’un anthropocentrisme enfantin175 ».
L’avenir de l’intelligence artificielle reste incertain, ce que l’on peut affirmer c’est qu’il ne
s’agit pas d’une « mode » du « monde de la tech’ » mais d’un mouvement global vers
une automatisation des tâches.
Les géants du numériques ou GAFAM sont les principaux acteurs dans le domaine de
l’intelligence artificielle et ils répondent à une logique capitaliste d’efficience des
algorithmes. Ils participent à l’ébullition dans le domaine du machine learning par leur
investissement massif.
Les IA présentent des bouleversements majeurs dans la société avec par exemple
l’adoption des voitures autonomes — Uber récupère ses données de navigation pour
ses voitures autonomes en préparation par le biais de ses livreurs Uber Eats176, La firme
va à son tour les remplacer au profit des véhicules autonomes. Elle va procéder à ce
changement sans se soucier de ses travailleurs précaires que Antonio Casilli définit
comme « piéçards des temps modernes177 ».
L’IA va donc poser des questions quant à l’avenir de l’emploi dans le monde. En effet,
elle présente un risque dans 75% des emplois du secteur tertiaire178. Benoit Hamon,
lors de sa campagne présidentielle de 2017, avait intégré ce bouleversement sociétal
en proposant le revenu universel, financé en partie par une taxation des algorithmes et
permettant une meilleure répartition des richesses.
Plus encore l’IA questionne notre propre rapport au travail.
Elle bouscule les méthodes de production de la chaine graphique : Chatonsky fait l’état
de générateur de logo, Jean Lassègue de générateur de grilles179, Indra Kupferschmid
de classification typographique automatiques180.
Est-ce que dans la création on va vers un changement brutal de paradigme comme la
crise qu’a connu l’art figuratif lors l’avènement de la photographie ?
Ainsi Pierre-Damien Huyghe indique « lorsqu'apparaît la photographie, Baudelaire
s’inquiète pour l’art, en l'occurrence la peinture181 ». Ce bouleversement technologique
donnera lieu à une remise en cause de l’art lui-même : ce qui participera à l’essor de
l’art moderne — Ernst Gombrish parle lui-même de « la rivalité entre la peinture et la
photographie182 ». Pour lui bien que peinture « classique » n’est pas comme sujet
exclusif la nature, le lien avec la nature offrait un ancrage183.
On retrouve un bouleversement semblable avec l’intégration de l’IA au processus
créatif. Emanuele Coccia, à propos des GAN indique :
« C’est de l’art car ça dépasse
les limites et les frontières du sens commun et de l’imagination telle qu’elle est pratiquée
par la plupart d’entre nous184 » — est-ce que l’intégration des IA remet-elle pas en cause
la notion d’auteur ?
Ce qui différencie le « technicien » et « l’artiste » réside dans l’intention, c’est ainsi que
l’histoire de l’art à différencier Muybridge et Man Ray. Mais qu’en est-il lorsque la
technique est automatique — non assujetti au désir de l’auteur ? À qui appartient la
création, s’agit-il à celui qui a effectué l’opération — lancer le programme, aux ayants
droits des données utilisées pour la génération, ou encore l’ayant droit de l’algorithme,
donc de l’outil ?
Plus encore, ces intelligences artificielles couplées avec des changements
d’architecture de processeurs, vont vers ce que les cybernéticiens définissent comme
la singularité.
L’intelligence Artificielle est censée connaître bientôt une explosion
comparable, qui va creuser un véritable trou dans la continuité du progrès.
L'accélération de son développement sera si considérable qu’elle provoquera
une “rupture dans le tissu spatio-temporel185
La singularité pour Catherine Malabou correspondrait au moment où l’intelligence
artificielle transcenderait l’humanité et serait autonome.
Il est important de noter que lorsque l’instant de la singularité sera atteint les algorithmes
dépasseront très rapidement la capacité humaine. Par analogie, en l’espace d’un an
entre la défaite de Lee Sedol face à Alpha Go et l’apparition d’Alpha Go Zero, les
algorithmes de jeu de go ont progressé de façon spectaculaire. Ainsi on peut supposer
qu’une croissance exponentielle suivra les algorithmes dépassant la singularité —
suivant quelque part la loi de Moore.
Catherine Malabou s’interroge sur les capacités de ces nouveaux ordinateurs :
Les ordinateurs de demain seront dotés de processeur capable de s’adapter
de s’auto transformer et d'intégrer leurs propres modifications. Le couple
d’assimilation-accommodation ne sera donc plus réservé à l’intelligence
naturelle186
Les prochains progrès de L’IA seraient liés aux capacités de plastique de l’intelligence
avec le développement de nouvelles puces « synaptiques ». Catherine Malabou
indique : « Ces programmes auront accès à leur propre programmation (au “source
code”) et pourront ainsi en manipuler les processus, de la même manière que nous
manipulons la génétique187 » ainsi elle met en parallèle la reprogrammation informatique
et celle de la génétique. Cette idée de reprogrammation génétique est une démarche
frôlant l’eugénisme : on retrouve donc une question éminemment éthique et morale
dans la démarche. La reprogrammation est initiée dans une optique d’efficience et de
rendement propre à une logique capitaliste de la machine.
Des projets de ce genre ont déjà lieu comme l’indique Éric Sadin :
« IBM qui ambitionne
de simuler quelques-unes des dimensions analytiques et réflexives de notre cerveau,
non exclusivement fondée sur le traitement brut de données, mais sur des strates
multiples d’intellection des phénomènes188 ». Il faut cependant prendre du recul par
rapport à la notion de « singularité », une forme de mirage des cybernéticiens qui nourrit
beaucoup de fantasme. Malabou l’affirme comme évidente et éminente — Chatonsky
propose avec Terre Seconde un discours sur l’effondrement de l’humanité face à la
machine inéluctable et inconscient. Mais s’agit-il encore de l’intelligence artificielle telle
qu’elle est pratiquée actuellement ?
En effet, celle-ci reste indéniablement lié au néolibéralisme et à la logique industrielle.
Avant l’entière autonomie des machines, quand bien même elle arriverait, celle-ci ont
tout de même besoin de nous. Comment comprendre l’essor des véhicules autonomes
sans clientèle ? Il y est question la pérennité des données sur lesquelles fonctionnent
les corpus d’apprentissage qui sont stockés sur des serveurs grâce à un apport
énergétiques fournit par la société ?
Remerciements
Je tiens tout d’abord à remercier mes professeurs référents Alexia de Oliveira
Gomes et Boris du Boullay qui m’ont suivi durant l’élaboration de ce mémoire et qui
m’ont donné de précieux conseils quant à l’élaboration du plan ainsi qu’aux recherches
théoriques et philosophiques.
J’adresse également toute ma sympathie à la classe de DSAA pour leur soutien moral
et intellectuel et l’aide qu’ils m’ont apportée.
Enfin je tiens à témoigner toute ma gratitude à mon père Frédéric Jely, pour m’avoir
apporté son retour critique sur le mémoire et d’avoir relu et corrigé mon mémoire.
Bibliographie
Ouvrage
CHANGEUX Jean-Pierre, Raison et Plaisir, Odile Jacob, sans lieu, 1994.
DE SAUSSURE Ferdinand, Cours de Linguistique Générale, Payot & Rivages, sans
lieu, coll. « Petite biblio payot Classique », 2016.
FRECHET Patrick, Jacques DONGUY, Chronique de Poésie numérique, Les
presses du réel, sans lieu, sans date.
GOLDSMITH Kenneth, L’écriture sans écriture, du langage à l’âge numérique, Jean
Boîte Éditions, sans lieu, sans date.
GOMBRICH Ernst, Histoire de l’Art, Phaidon, sans lieu, 1963.
HAYLES Katherine, Parole, écriture, code, Les presses du réel, sans lieu, sans
date.
HAYLES Katherine, Writing Machine, The MIT press, sans lieu, sans date.
KRZYWKOWSKI Isabelle, Machine à écrire : littérature et technologies du XIXE au
XXIE siècle, UAG Éditions, sans lieu, sans date.
LUDOVICO Alessandro, Post Digital Print, La mutation de l’édition depuis 1894, B42
éd., sans lieu, sans date.
MALABOU Catherine, Métamorphose de l’intelligence, que faire de leur cerveau
bleu, Presses Universitaires de France, sans lieu, 2017.
MORTON Timothy, La Pensée écologique, Cécile Wajsbrot (trad.), Zulma, sans
lieu, sans date.
NEUTRES Jérôme et Laurence BERTRANC DORLEAC, Artistes & robots, sans lieu,
RMN-Grand Palais, sans date.
PLATON, Le Banquet, Phèdre, Emile Chambry (trad.), sans lieu, Flammarion, 1992.
SADIN Éric, L’humanité Augmentée, l’administration numérique du monde, Édition
l’Échappée, sans lieu, sans date.
TARDIEU Jean, La comédie du langage suivi de La triple mort du Client, Folio, sans
lieu, sans date.
WEILL Alain, Le Design graphique, sans lieu, Gallimard, coll. « Découvertes
Gallimard », 2003.
Billets de Blog
ATKENS Memo, « Learning to See », sur Memo Akten | Mehmet Selim Akten |
The Mega Super Awesome Visuals Company, sans date (en ligne :
http://www.memo.tv/portfolio/learning-to-see/ ; consulté le 20 décembre
2019).
GIRAUD Thibaut, « À chacun sa morale ? | Relativisme vs. réalisme | Grain de philo
#12 », sur Monsieur Phi, 19 août 2017 (en ligne :
https://monsieurphi.com/2017/08/19/a-chacun-sa-morale-relativisme-vsrealisme-grain-de-philo-12/ ; consulté le 9 février 2020).
MEYSSONNIER Florence, « Pierre Huyghe | Zérodeux / 02 », sur Pierre Huyghe |
Zérodeux / 02, sans date (en ligne : https://www.zerodeux.fr/reviews/pierrehuyghe-2/ ; consulté le 11 novembre 2019).
MOULON Dominique, « Du médium numérique au Fresnoy [ Dominique Moulon ] »,
sur Du médium numérique au Fresnoy [ Dominique Moulon ], sans date (en
ligne : http://www.mediaartdesign.net/FR_fresn.html ; consulté le 28
septembre 2019).
O’REILLY Tim, « What Is Web 2.0 », sans date (en ligne :
https://www.oreilly.com/pub/a//web2/archive/what-is-web-20.html ; consulté
le 5 février 2020).
Articles scientifiques
BATES David, « Automaticity, plasticity, and the Deviant Origins of Artificial
Intelligence », Plasticity and Pathology, coll. « Fordham University Press »,
2016.
BOJANOWSKI Piotr, Edouard GRAVE, Armand JOULIN et Tomas MIKOLOV,
« Enriching Word Vectors with Subword Information », arXiv:1607.04606
[cs], 19 juin 2017 (en ligne : http://arxiv.org/abs/1607.04606 ; consulté le 10
décembre 2019). ArXiv: 1607.04606.
GOODFELLOW Ian J., Jean POUGET-ABADIE, Mehdi MIRZA, Bing XU, David WARDEFARLEY, Sherjil OZAIR, Aaron COURVILLE et Yoshua BENGIO, « Generative
Adversarial Networks », arXiv:1406.2661 [cs, stat], 10 juin 2014 (en ligne :
http://arxiv.org/abs/1406.2661 ; consulté le 29 septembre 2019). ArXiv:
1406.2661.
ISOLA Phillip, Jun-Yan ZHU, Tinghui ZHOU et Alexei A. EFROS, « Image-to-Image
Translation with Conditional Adversarial Networks », arXiv:1611.07004 [cs],
26 novembre 2018 (en ligne : http://arxiv.org/abs/1611.07004 ; consulté le 20
décembre 2019). ArXiv: 1611.07004.
MIKOLOV Tomas, Kai CHEN, Greg CORRADO et Jeffrey DEAN, « Efficient Estimation
of Word Representations in Vector Space », arXiv:1301.3781 [cs], 6
septembre 2013 (en ligne : http://arxiv.org/abs/1301.3781 ; consulté le 1er
décembre 2019). ArXiv: 1301.3781.
RADFORD Alec, Luke METZ et Soumith CHINTALA, « Unsupervised Representation
Learning with Deep Convolutional Generative Adversarial Networks »,
arXiv:1511.06434 [cs], 7 janvier 2016 (en ligne :
http://arxiv.org/abs/1511.06434 ; consulté le 10 décembre 2019). ArXiv:
1511.06434.
RAUNAK Vikas, « Simple and Effective Dimensionality Reduction for Word
Embeddings », arXiv:1708.03629 [cs], 21 novembre 2017 (en ligne :
http://arxiv.org/abs/1708.03629 ; consulté le 5 décembre 2019). ArXiv:
1708.03629.
VINYALS Oriol, Alexander TOSHEV, Samy BENGIO et Dumitru ERHAN, « Show and
Tell: A Neural Image Caption Generator », arXiv:1411.4555 [cs], 20 avril
2015 (en ligne : http://arxiv.org/abs/1411.4555 ; consulté le 24 octobre 2019).
ArXiv: 1411.4555.
WEIZENBAUM Joseph, « Eliza - A computer Program for the Study of Natural
Language Communication Between Man and Machine », Eliza - A computer
Program for the Study of Natural Language Communication Between Man
and Machine, janvier 1966 (en ligne :
https://web.stanford.edu/class/linguist238/p36-weizenabaum.pdf ; consulté
le 16 décembre 2019).
Articles de journaux
Anonyme, « Microsoft muselle son robot «Tay», devenu nazi en 24 heures »,
Libération.fr, 25 mars 2016 (en ligne :
https://www.liberation.fr/futurs/2016/03/25/microsoft-muselle-son-robot-taydevenu-nazi-en-24-heures_1441963 ; consulté le 17 décembre 2019).
PROTAIS Marine, « 23 millions de Chinois ne peuvent plus voyager à cause de leur
mauvaise note citoyenne », L’ADN, 4 mars 2019 (en ligne :
https://www.ladn.eu/tech-a-suivre/23-millions-chinois-prives-voyages-scoresocial/ ; consulté le 21 décembre 2019).
Articles
HUYGHE Pierre-Damien, « L’outil et la Méthode », Millieu, no 33, 1988.
KUPFERSCHMID Indra, « Une IA pour la classification typographique », Back
Office, vol. 2, 2017.
LASSEGUE Jean, « Des grilles et des rubans », Back Office, vol. 2, sans date.
NOVA Nicolas et Joël VACHERON, « DADA DATA, Une introduction aux culture
algorithmiques », Kieran Aaron (trad.), BACK OFFICE, Penser, classer,
représenter, no 2, sans date.
RUBIN Dan, « Tourner la page - Off the Page », Mylène Czyzbiak (trad.), Back
Office, Ecrire L’écran, no 3, 2019.
Filmographie
POULAIN Henri, « Algocratie : L’inégalité programmée - #DATAGUEULE 84 »,
dans l’émission Data gueule, no 84, 2018, 11:07 (en ligne :
https://www.youtube.com/watch?v=oJHfUv9RIY0 ; consulté le 16 décembre
2019).
POULAIN Henri et Julien GOETZ, « Invisibles Roulez jeunesse », dans l’émission
Invisibles - Les travailleurs du clic, no 1, Fevrier 2020 (en ligne :
https://www.france.tv/slash/invisibles/saison-1/1274809-roulezjeunesse.html ; consulté le 17 février 2020).
POULAIN Henri et Julien GOETZ, « Au-delà du clic », dans l’émission Invisibles -
Les travailleurs du clic, no 4, sans date (en ligne :
https://www.france.tv/slash/invisibles/saison-1/1274819-au-dela-duclic.html ; consulté le 17 février 2020).
« François Le Lionnais et l’Oulipo », dans l’émission Italiques, 1972 (en ligne :
http://www.ina.fr/video/I10322578 ; consulté le 18 décembre 2019).
Conférences et vidéos web
BEAUDE Boris, Intervention de Boris BEAUDE au Colloque sur L’intelligence
artificielle et l’avenir du travail, Laboratoire d’études des sciences et des
techniques (STSlab), Institut des sciences sociales, Université de
Lausanne, 22 mars 2018, 31:37 (en ligne :
https://www.youtube.com/watch?v=JCP0Pic5WYc ; consulté le 11
décembre 2019).
CHOMSKY Noam, Qu’est le langage, et en quoi est-ce important ?, 19e Congrès
international des linguistes à Genève en 2013, Uni Dufour, sans date (en
ligne : https://www.youtube.com/watch?v=-wJDf9gAWW4 ; consulté le 18
janvier 2020).
DEBBACHE Karim, CROSSED - 11 - WarGames, sans date, 13:16 (en ligne :
https://www.youtube.com/watch?v=Z--AJ2KsAjg ; consulté le 5 décembre
2019).
GALLERIES Serpentine, Pierre Huyghe: UUmwelt, sans date (en ligne :
https://www.youtube.com/watch?v=enx-vyWn7UU ; consulté le 11 novembre
2019).
GIRAUD Thibaut, IMAGES SUBLIMINALES | Grain de philo #15 (Ep.1), 2017,
11:36 (en ligne : https://www.youtube.com/watch?v=alGQ-g2-FxM ; consulté
le 10 février 2020).
GIRAUD Thibaut, À CHACUN SA MORALE ? | Relativisme vs. réalisme | Grain de
philo #12, sans date, 13:46 (en ligne :
https://www.youtube.com/watch?v=7KmAKVaO-Xc& ; consulté le 10 février
2020).
GIRAUD Thibaut et Lê NGUYÊN HOANG, 7 expériences de pensée morales (ft.
Science4All) - Serez-vous utilitariste jusqu’au bout ?, sans date, 17:28 (en
ligne : https://www.youtube.com/watch?v=AZBDMN5wZ8&list=PLuL1TsvlrSndG1xYLRsaNvSM46lOkOg2W&index=2 ; consulté le 9
février 2020).
LECUN Yann, Réseaux récurrents. Applications Au traitement du langage naturel,
Collège de France, 1er avril 2016, 54:18 (en ligne : https://www.college-defrance.fr/site/yann-lecun/course-2016-04-01-11h00.htm ).
LECUN Yann, Informatique et sciences numériques - Leçon inaugurale, Collège
de France, 4 février 2016.
LOUAPRE David, La fourmi de Langton — Science étonnante #21, sans date, 8:48
(en ligne : https://www.youtube.com/watch?v=qZRYGxF6D3w ; consulté le 4
février 2020).
LOUAPRE David, Le deep learning — Science étonnante #27, sans date, 20:06 (en
ligne : https://www.youtube.com/watch?v=trWrEWfhTVg ; consulté le 28
novembre 2019).
LOUAPRE David, Une intelligence artificielle peut-elle être créative ? — Science
étonnante #57, sans date, 21:30 (en ligne :
https://www.youtube.com/watch?v=xuBzQ38DNhE ; consulté le 16
décembre 2019).
NORTH Cyrius, Le Coup de Phil’ #14 - L’empirisme de John Locke, 15 janvier 2015,
4:54 (en ligne : https://www.youtube.com/watch?v=1Xr9s5xy3Sc ; consulté
le 3 février 2020).
NORTH Cyrius, L’Habitus de Pierre Bourdieu - Le Coup de Phil’ #27, sans date,
5:36 (en ligne : https://www.youtube.com/watch?v=c67GEYsM2yA ; consulté
le 6 février 2020).
RILEY Sean, Generative Adversarial Networks (GANs) - Computerphile, sans date,
21:20 (en ligne : https://www.youtube.com/watch?v=Sw9r8CL98N0 ;
consulté le 10 décembre 2019).
RILEY Sean, Vectoring Words (Word Embeddings) - Computerphile, sans date,
16:55 (en ligne : https://www.youtube.com/watch?v=gQddtTdmG_8&t=1s ;
consulté le 7 décembre 2019).
SERPENTINE GALLERIES, Pierre Huyghe: UUmwelt, sans date, 7:18 (en ligne :
https://www.youtube.com/watch?v=enx-vyWn7UU ; consulté le 11 novembre
2019).
Informatique et sciences numériques - Leçon inaugurale, Collège de France, 4
février 2016.
Match 2 - Google DeepMind Challenge Match: Lee Sedol vs AlphaGo, sans date,
5:52:30 (en ligne : https://www.youtube.com/watch?v=lGsfyVCBu0&feature=youtu.be&t=4693 ; consulté le 1er octobre 2019). Le 37
coup de la 2eme manche commence au timecode 1:18:13.
Qu’est-ce que l’imagination (artificielle)? - Joyeux-Prunel, Cadain, Chatonsky,
Ecole Normal Supérieur, sans date, 2:03:42 (en ligne :
https://www.youtube.com/watch?v=t6Uh5d9-hnY ; consulté le 1er décembre
2019).
Sonder la « Terre Seconde », de Grégory Chatonsky [Version 6 minute], Palais
de Tokyo, sans date, 6:00 (en ligne :
https://www.youtube.com/watch?v=JRBkwQwy6n0&list=PL7VgX_eKMbTC90H9j-ggWI5WFqq9eqB5&index=4&t=270s ; consulté le 16 novembre
2019).
Terre Seconde - Grégory Chatonsky et Emanuele Coccia - Audi Talents, sans
date, 42:48 (en ligne : https://www.youtube.com/watch?v=90EPfupUsAs ;
consulté le 30 septembre 2019).
Site Web
BENAZDIA Norédine, « Je suis Norman, la première intelligence artificielle
psychopathe », sans date (en ligne : https://usbeketrica.com/article/normanpremiere-intelligence-artificielle-psychopathe ; consulté le 17 novembre
2019).
BONECHI Bruno, « Intelligence artificielle : quel impact sur les emplois ? », sur
Journal du Net, sans date (en ligne :
https://www.journaldunet.com/solutions/reseau-social-dentreprise/1209489-intelligence-artificielle-quel-impact-sur-les-emplois/ ;
consulté le 16 février 2020).
CHARTIER Mathieu, « Lecture & compréhension : une IA dépasse l’Homme pour la
première fois », 16 janvier 2018 (en ligne :
https://www.lesnumeriques.com/vie-du-net/lecture-comprehension-iadepasse-homme-pour-premiere-fois-n70519.html ; consulté le 10 décembre
2019).
CROUSPEYRE Charles, « Comment les Réseaux de neurones à convolution
fonctionnent », sur Medium, 19 juillet 2017 (en ligne :
https://medium.com/@CharlesCrouspeyre/comment-les-r%C3%A9seauxde-neurones-%C3%A0-convolution-fonctionnent-b288519dbcf8 ; consulté le
7 décembre 2019).
FERNANDEZ RODRIGUEZ Laura, « Un algorithme peut-il prédire le risque de récidive
des détenus ? », sur Un algorithme peut-il prédire le risque de récidive des
détenus ?, sans date (en ligne : https://usbeketrica.com/article/unalgorithme-peut-il-predire-le-risque-de-recidive-des-detenus ; consulté le 16
décembre 2019).
HO Kevin, « Organizing the World of Fonts with AI - IDEO Stories - Medium », sur
Organizing the World of Fonts with AI - IDEO Stories - Medium, sans date
(en ligne : https://medium.com/ideo-stories/organizing-the-world-of-fontswith-ai-7d9e49ff2b25 ; consulté le 28 septembre 2019).
JEFF LARSON Julia Angwin, « How We Analyzed the COMPAS Recidivism
Algorithm », sur ProPublica, 23 mai 2016 (en ligne :
https://www.propublica.org/article/how-we-analyzed-the-compas-recidivismalgorithm ; consulté le 18 décembre 2019).
JOURNAL DU NET, « La loi de Moore définie simplement », sans date (en ligne :
https://www.journaldunet.fr/web-tech/dictionnaire-duwebmastering/1203331-loi-de-moore-definition-traduction/ ; consulté le 18
janvier 2020).
JULIA ANGWIN Jeff Larson, « Machine Bias », sur ProPublica, 23 mai 2016 (en
ligne : https://www.propublica.org/article/machine-bias-risk-assessments-incriminal-sentencing ; consulté le 16 décembre 2019).
KLOETZLI Sophie, « « Infinite Skulls » : l’expo qui fait dialoguer art et intelligence
artificielle », sans date (en ligne : https://usbeketrica.com/article/infinite-skullsexpo-dialogue-art-ia ; consulté le 10 décembre 2019).
LINN Allisson, « Microsoft creates AI that can read a document and answer
questions about it as well as a person », sur The AI Blog, 16 janvier 2018 (en
ligne : https://blogs.microsoft.com/ai/microsoft-creates-ai-can-readdocument-answer-questions-well-person/ ; consulté le 10 décembre 2019).
MEYSSONNIER Florence, « Pierre Huyghe Zérodeux / 02 », sur Pierre
Huyghe Zérodeux / 02, sans date (en ligne :
https://www.zerodeux.fr/reviews/pierre-huyghe-2/ ; consulté le 11 novembre
2019)
SHEKHAR Amit, « Understanding The Recurrent Neural Network », sur Medium, 6
décembre 2019 (en ligne : https://medium.com/mindorks/understanding-therecurrent-neural-network-44d593f112a2 ; consulté le 4 février 2020).
« ImageNet Large Scale Visual Recognition Competition 2012 (ILSVRC2012) »,
sur Image Net, sans date (en ligne : http://www.imagenet.org/challenges/LSVRC/2012/results.html ; consulté le 2 décembre 2019).
« Internet Live Stats - Internet Usage & Social Media Statistics », sans date (en
ligne : https://www.internetlivestats.com/ ; consulté le 5 février 2020).
« Norman by MIT Media Lab », sur Norman by MIT Media Lab, sans date (en
ligne : http://norman-ai.mit.edu ; consulté le 17 décembre 2019).
Post de Forum
« R/MachineLearning - [P] X Degrees of Separation | Google Arts & Culture », sur reddit, sans date (en ligne : https://www.reddit.com/r/MachineLearning/comments/5d59gu/p_x_degrees _of_separation_google_arts_culture/ ; consulté le 16 décembre 2019).
Documentation de bibliothèques
BARRAT Robbie, Robbiebarrat/Sculpture-GAN, sans lieu, 2019 (édition originale :
2017).
WOOLF Max, Minimaxir/textgenrnn, sans lieu, 2019 (édition originale : 2017).
Puppeteer/puppeteer, sans lieu, Puppeteer, 2020 (édition originale : 2017).